1. ResNet의 핵심 아이디어인 Residual Learning 개념을 정리하세요.
[ 개념 ]
* 기존의 전체 함수 H(x)를 직접 학습하는 방식이 아닌 입력 x와 목표 출력 H(x) 간의 잔차에 해당하는 함수 F(x) = H(x) - x 를 학습하는 방식
* 최종 출력 : H(x) = F(x) + x
* 네트워크가 굳이 H(x) 전체를 학습하지 않고도 identity function에 가까운 출력을 자연스럽게 보정할 수 있다.
[ 왜 필요한가? ]
1. 깊은 네트워크의 성능 저하 문제 (Degradation Problem)
* 일반적인 CNN은 네트워크 깊이가 증가할수록 오히려 학습 정확도가 낮아지는 문제가 발생했다. 이는 과적합 때문이 아니라, 깊은 네트워크가 항등 함수조차 제대로 근사하지 못하는 최적화 실패 문제라는 것이 핵심 진단이다.
2. identity function이 최적일 때 잔차 함수 F(x)는 0이 되면 된다.
* 만약 입력 x를 그대로 출력으로 내보내는 것이 가장 좋은 경우라면, 기존 CNN은 이를 복잡한 비선형 함수로 억지로 근사해야함.
* F(x) = 0 으로 학습하면 즉시 y = x (항등함수, identity function) 가 구현되므로 최적호가 훨씬 간단해지고 안정화 된다.
[ 구조적 구현 ]
ResNet은 Residual Learning을 실제로 구현하기 위해 두 가지 residual block 구조를 사용한다.
1. 일반 Residual block (Figure 2, ResNet-18/34에서 사용)
- 구성 : 3×3 Conv → ReLU → 3×3 Conv
- 입력과 출력의 shape이 가아 identity shortcut을 사용할 수 있음
- 구조가 단순하여 shallow 네트워크에 적합
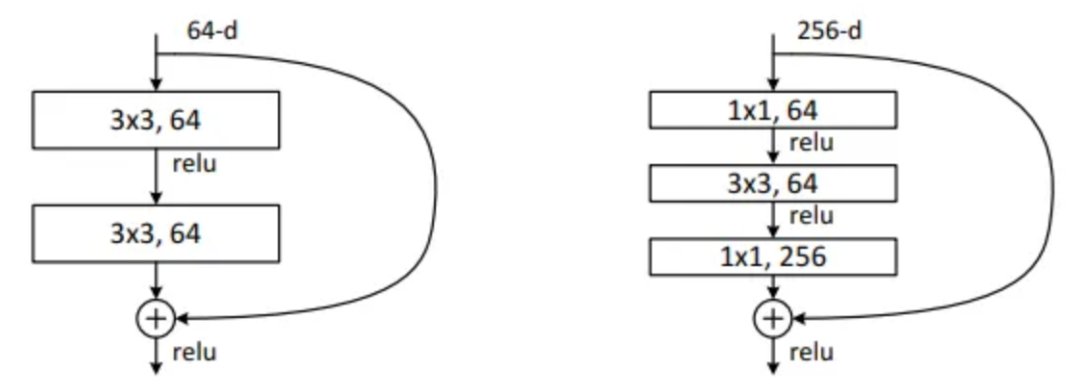
2. Bottleneck block (Figure 5, ResNet-50 이상에서 사용)
- 구성 : 1×1 Conv (축소) → 3×3 Conv → 1×1 Conv (확장)
- 계산량 절감과 효율적인 파라미터 사용을 위해 설계됨
- 대부분의 경우 입력과 출력의 채널 수가 다르기 때문에 projection shortcut을 사용하여 shortcut 연결을 구현
- 깊은 네트워크에서도 연산량을 늘리지 않고 Residual Learning을 효율적으로 적용할 수 있도록 도와주는 구조적 최적화
[ 수학적 직관 ]
- 모든 정규 신경망은 범용 근사기 (universal approximator : 충분한 표현 능력을 가진 모델이 임의의 연속 함수를 원하는 정확도 내에서 근사할 수 있다는 성질) 이기 때문에 잔차 함수 F(x) = H(x) - x 역시 근사 가능
- 그러나 H(x)를 직접 근사하는 것보다, x와의 차이 F(x)를 학습하는 편이 파라미터 공간이 작고 최적화가 빠름
- 실험적으로도 ResNet에서 학습된 F(x)의 출력 분산이 매우 작다는 점은 실제로도 잔차만 학습되고 있다는 증거라고 볼 수 있다.
[ 실질적 효과 ]
- ResNet 구조는 Residual Learning 덕분에 100층이 넘는 네트워크를 안정적으로 학습할 수 있게 되었다.
- CIFAR-10, ImageNet 등 다양한 실험에서 일반적인 plain CNN 보다 더 깊으면서도 더 낮은 error rate를 달성함
2. 일반적인 CNN과의 차이점, 그리고 skip connection이 필요한 이유
2-1. 일반적인 CNN (Plain Network)의 구조적 특징
- 일반적인 CNN은 연속된 합성곱 레이어를 순차적으로 쌓아나가는 구조
- 이 구조에서 각 레이어가 입력 x를 점점 더 복잡한 형태의 표현으로 (추상화) 바꾸는 것이 목표
- 학습 대상은 전체 함수 H(x)이며, 이 함수는 모든 레이어를 통과한 최종 결과
2-2. 깊은 plain CNN의 한계 : Degradation Problem
논문에서는 일반 CNN을 깊게 만들면 성능이 좋아질 것이라는 가정이 반드시 성립하지 않음을 실험으로 증명한다.
* 실험 : CIFAR-10 / ImageNet (논문 Fig.1, Fig.4 참고)

- 20-layer plain net보다 56-layer plain net의 training error가 더 높아지는 현상이 나타남
- 이는 overfitting이 아닌, 최적화 실패로 발생한 현상임을 지적함
2-3. ResNet의 구조적 전환: Residual Learning & Skip Connection
ResNet은 이러한 문제를 해결하기 위해 다음과 같은 개념을 도입한다.
* 아이디어 : 학습할 목표를 H(x)가 아니라 F(x) = H(x) - x로 바꾸자 (= residual function)
- 즉, 원하는 출력 H(x)를 직접 학습하는 대신, 입력 x에 어떤 변화 F(x)를 더해야 H(x)가 되는지를 학습
* 구조적 구현 : skip connection
- 위 아이디어 ( residual ) 학습을 구현하는 구조가 skip connection
- Residual block의 형태 : y = F(x) + x
=> 학습할 대상은 F(x), 그리고 skpi connection을 통해 x를 그대로 더한다.
2-4. 일반 CNN과 ResNet의 구조적 차이
* 학습 목표의 차이
- 일반 CNN: 입력 x를 여러 층을 거쳐 직접 원하는 함수 H(x)를 근사하도록 학습
- ResNet: 입력과 출력 간의 차이인 잔차 함수 F(x)=H(x)-x 만을 학습
=> ResNet은 전체 함수를 학습하는 것이 아니라 “얼마나 더할지를” 학습함으로써 최적화 부담을 경감
* 정보 전달 방식
- 일반 CNN: 모든 입력은 각 층을 연속적으로 통과하며 정보가 점진적으로 손실됨
- ResNet: 입력 x를 skip connection을 통해 출력에 직접 더함으로써, 정보가 원형 그대로 보존됨
= > 중요 feature의 손실 없이 깊은 층까지 직접적인 정보 흐름을 유지할 수 있음
* 항등 함수 근사의 용이성
- 일반 CNN: H(x)= 와 같은 항등 함수조차 여러 weight layer를 통해 어렵게 근사해야 함
- ResNet: F(x) 으로 학습하면 항등 함수가 즉시 구현됨
=> 네트워크가 불필요한 왜곡 없이 안정적인 초기 상태를 유지할 수 있음
* gradient 흐름과 역전파 안정성
- 일반 CNN: 네트워크가 깊어질수록 gradient가 소실되거나 왜곡되어 학습이 불안정해짐
- ResNet: skip connection 경로를 통해 gradient가 직접 앞쪽 층까지 전달되며, 학습 초기에 gradient 흐름이 차단되지 않음
=> 특히, 초심층 네트워크(>50 layer)에서도 training error가 감소함을 실험적으로 입증
* 최적화 관점에서의 함수 공간 재구성
- 일반 CNN: 전체 비선형 함수 공간 H를 탐색해야 하므로, 최적화 landscape가 복잡하고 깊음
- ResNet: 함수 공간을 입력 기준으로 재정의된 residual 공간 F(x)에서 탐색하므로 더 평탄하고 수렴하기 쉬운 landscape 위에서 학습 진행
=> 논문에서는 이를 일종의 preconditioning 효과로 해석함
2-5. Skip Connection의 실험적 필요성 증명

- Plain network (18, 34층): deeper network의 training error가 증가함
- R esNet (18, 34층): deeper network일수록 training error가 감소함
- skip connection이 없으면 더 깊은 네트워크조차 학습 실패하지만, 있을 경우 학습은 더 깊어질수록 안정적이다.
2-6. Skip Connection이 필요한 이론적 이유
(1) 최적화 관점 : 함수 근사보다는 항등에서의 잔차 학습이 더 쉬움
- 항등 함수가 최적인 상황에서 plain CNN은 H(x)=를 그대로 구현하는 것이 어려움. 그러나 ResNet은 단지 F(x)=0F(x) = 0만 학습하면 됨
(2) gradient 흐름 관점: Vanishing Gradient 문제를 완화
- 역전파 시에도 입력까지 직접 경로가 존재하기 때문에 깊은 층까지 gradient가 전달되어 학습 안정성 증가
(3) 표현력 분해: 네트워크 전체가 복잡한 함수가 아니라, 부분 부분의 변화만 담당
- 실제로 논문 Fig.7(p.8)은 Residual block의 출력 분산이 매우 작다는 것을 보여줌
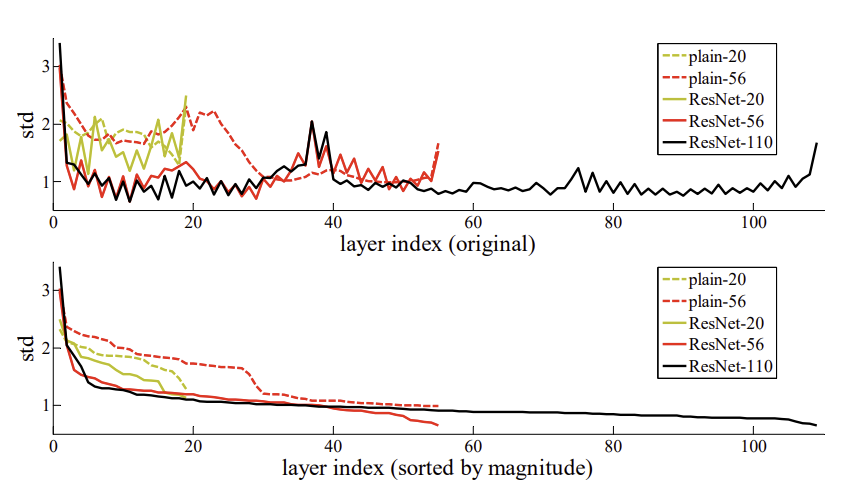
=> 네트워크가 큰 변화가 아닌 작은 수정만 학습하고 있다는 증거
결론 :
* 일반 CNN은 깊어질수록 학습이 어려워지며, gradient 소실 및 항등 함수 근사의 비효율성 문제를 가짐
* ResNet은 skip connection을 통해 입력 정보를 그대로 전달하면서 학습할 함수 공간을 "잔차"로 제한
* 이로인해 (1) 학습이 쉬워지고 (2) gradient가 깊은 층까지 전달되며 (3) 항등함수부터 시작하여 안정적 최적화 가능
3. ResNet이 깊은 네트워크에서 발생하는 문제(vanishing gradient 등)를 어떻게 해결했는지 기술하세요.
문제 1. Vanishing Gradient Problem
* 정의 : 레이어가 깊어질수록 gradient가 앞쪽 층까지 도달하지 못해 학습이 멈추는 현상
* 출처 : p.2, 수식 유도 및 구조적 설명
* 추가 맥락 : BN, ReLU 등으로 어느 정도 해결되었지만, 아주 깊은 네트워크에선 여전히 심각
* ResNet의 해결 방식
- skip connection을 도입하여 입력을 출력으로 직접 더함
- 역전파 시 gradient가 항등경로를 따라 직접 전파됨

문제 2. Degradation Problem (성능 저하)
* 정의 : 네트워크를 더 깊게 만들었더니 오히려 training error가 증가하는 현상
* 출처 : Figure 1 (p.1), Figure 4 (p.5)
* ResNet의 해결 방식
- Residual 구조에서 F(x)=0이면 y=x. 즉 항등 함수를 구조적으로 표현 가능하다.
- 더 깊은 레이어가 꼭 무언가를 학습하지 않아도 됨. 불필요한 학습 부담이 제거되기 때문에 성능 저하 없이 네트워크 깊이 증가 가능
문제 3. Extremely Slow Convergence (수렴 속도 저하)
* 정의 : 일부 deep plain net은 학습은 가능하나, 수렴이 지나치게 느려 실질적인 학습 실패로 이어짐
* 출처 : p.2 - “We conjecture that the deep plain nets may have exponentially low convergence rates.”
* ResNet의 해결 방식
- 잔차함수를 학습함으로써 학습해야 할 함수 공간을 단순화함.
- 초기 weigth 기준으로 F(x)≈0 에서 시작하기 때문에 더 빠르고 안정적인 수렴 가능 (preconditioning effect라고 해석)
문제 4. 정보 소실 및 feature representation의 왜곡
* 정의 : 깊은 네트워크일수록 feature가 왜곡되거나 의미가 사라지는 경향
* 출처 : Figure 7 (p.8) — residual block 출력 분산이 작음
* ResNet의 해결 방식
- 입력 x를 그대로 다음 블록에 더해줌으로써 정보를 보존하며 변형
- 각 블록은 기존 정보에 조금씩 더하는 방식으로 학습 > deep feature alignment 유지
2025.08.08 - [논문 리뷰] - [논문 구현] Deep Residual Learning for Image Recognition
'논문 리뷰' 카테고리의 다른 글
| [논문 구현] Deep Residual Learning for Image Recognition (3) | 2025.08.08 |
|---|---|
| AlexNet 논문에서 ReLU를 사용한 이유 직접 실험해보기, Sigmoid 함수의 정확도는 왜 이렇게 나왔을까? (3) | 2025.08.04 |
| AlexNet 아키텍처 직접 구현 및 CPU vs GPU 실험 (정확도가 다르게 나온 이유?) (2) | 2025.08.04 |
| ImageNet Classification with Deep Convolutional Neural Networks(2012) | AlexNet 논문 핵심 내용 요약 (4) | 2025.08.03 |
| 딥러닝 논문 가이드 _ 딥러닝 전체 (1) | 2025.08.03 |