1. 목표
AlexNet 직접 구현
torchvision.models의 AlexNet을 사용하지 않고, 논문 구조를 참고해 직접 CNN 모델을 구현 (Optimizer은 Adam으로 변경)
사용할 데이터 셋은 kaggle의 포트홀 데이터 선택
CPU vs GPU 학습 성능 비교 실험
동일한 조건으로 CPU와 GPU 각각에서 학습 진행
학습 시간과 정확도를 표 또는 그래프로 비교 분석
1. AlexNet 직접 구현
# kaggle API를 통해 데이터셋 불러오기
from google.colab import files
files.upload() # kaggle.json 업로드 창 표시
!mkdir -p ~/.kaggle
!cp kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.json
!kaggle datasets download atulyakumar98/pothole-detection-dataset
!unzip -q pothole-detection-dataset.zip
import os, glob, shutil
import torch
import torch.optim as optim
import matplotlib.pyplot as plt
import torch.nn as nn
import torch.nn.functional as F
from PIL import Image
from sklearn.model_selection import train_test_split
from torchvision import transforms, datasets
from torchvision.transforms import transforms
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
from torch.utils.data import DataLoader, Dataset
from torch.optim.lr_scheduler import StepLR
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
categories = ['normal', 'potholes']
train_ratio = 0.8
random_state = 42
split_root = 'data_split' # 데이터를 분리해 저장할 폴더의 경로 지정
# train과 test 폴더 생성
for phase in ['train','test']:
for cls in categories:
# 경로 생성 : data_split/train/normal, data_split/test/potholes 등의 폴더 생성
our_dir = os.path.join(split_root, phase, cls)
os.makedirs(our_dir, exist_ok=True) # 폴더가 없다면 새로 생성 (있으면 무시)
# 각각 카테고리별 이미지 분리 작업 시작
for cls in categories:
# 현재 카테고리 폴더 내에 있는 모든 이미지 파일의 경로 목록 가져옴
src_paths = glob.glob(os.path.join(cls, '*'))
# train_ratio 비율로 train/test 나눔
train_paths, test_paths = train_test_split(
src_paths,
train_size=train_ratio,
random_state=random_state,
shuffle=True
)
# 이미지 파일을 각각의 목적지 폴더로 복사 (학습용 이미지)
for src in train_paths:
# 복사할 목적지 경로 지정 (data_split/train/카테고리명/파일명)
dst = os.path.join(split_root, 'train', cls, os.path.basename(src))
shutil.copy2(src, dst) # 실제 파일 복사 작업 수행
# 이미지 파일을 각각의 목적지 폴더로 복사 (테스트용 이미지)
for src in test_paths:
# 복사할 목적지 경로 지정 (data_split/test/카테고리명/파일명)
dst = os.path.join(split_root, 'test', cls, os.path.basename(src))
shutil.copy2(src, dst) # 실제 파일 복사 작업 수행
print(" data_split 아래에 train/test 분류가 완료되었습니다!")- 폴더를 만들어서, train/test 데이터 분리
for phase in ['train', 'test']:
for cls in categories:
pattern = os.path.join(split_root, phase, cls, '*')
count = len(glob.glob(pattern))
print(f"{phase:5s} / {cls:8s} : {count} images")
=================
train / normal : 281 images
train / potholes : 263 images
test / normal : 71 images
test / potholes : 66 images
# 약간의 차이는 있지만 클래스 불균형이라고 보기엔 위험이 크지 않을 정도라고 판단됨.
데이터 전처리 (Transform) 정의, DataLoader 생성
# 1) 전처리(transform) 정의
data_transforms = {
'train': transforms.Compose([
transforms.Resize((224, 224)), # 모든 이미지를 224×224 크기로 통일
transforms.RandomHorizontalFlip(), # 랜덤 좌우 반전 (데이터 다양성 ↑)
transforms.ToTensor(), # [0,255] 픽셀 → [0.0,1.0] 텐서
transforms.Normalize( # RGB 채널별 평균/표준편차로 정규화
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
]),
'test': transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
}
# 2) ImageFolder로 데이터셋 생성
image_datasets = {
phase: ImageFolder(
root=os.path.join(split_root, phase),
transform=data_transforms[phase]
)
for phase in ['train', 'test']
}
# 3) DataLoader 생성 (미니배치 단위로 자동으로 로드)
dataloaders = {
phase: DataLoader(
dataset=image_datasets[phase],
batch_size=32, # 배치 크기: 한 번에 32장씩
shuffle=(phase == 'train') # train일 때만 섞어서 로드
)
for phase in ['train', 'test']
}
# 4) 데이터셋 크기 및 클래스 이름 출력
dataset_sizes = {phase: len(image_datasets[phase]) for phase in ['train', 'test']}
class_names = image_datasets['train'].classes
print(f"Train size: {dataset_sizes['train']} images")
print(f"Test size: {dataset_sizes['test']} images")
print("Classes:", class_names)
AlexNet 모델 직접 구현하기
class AlexNetCustom(nn.Module):
def __init__(self, num_classes=2):
super(AlexNetCustom, self).__init__()
# 1) 특징 추출부 (feature extractor)
self.features = nn.Sequential(
# --- 1st conv block ---
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2), # 224→55
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, alpha=1e-4, beta=0.75, k=2),
nn.MaxPool2d(kernel_size=3, stride=2), # 55→27
# --- 2nd conv block ---
nn.Conv2d(64, 192, kernel_size=5, padding=2), # 27→27
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, alpha=1e-4, beta=0.75, k=2),
nn.MaxPool2d(kernel_size=3, stride=2), # 27→13
# --- 3rd,4th,5th conv blocks ---
nn.Conv2d(192, 384, kernel_size=3, padding=1), # 13→13
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1), # 13→13
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1), # 13→13
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2) # 13→6
)
# 2) 분류부 (classifier)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(256 * 6 * 6, 4096), # 풀링 후 feature 크기 flatten
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes) # 최종 클래스 수 (normal/potholes)
)
def forward(self, x):
x = self.features(x) # 컨볼루션 + 풀링
x = x.view(x.size(0), 256 * 6 * 6) # 4D → 2D (batch, features)
x = self.classifier(x) # 완전연결 + 드롭아웃
return x
# 모델 생성 및 장치 할당
model = AlexNetCustom(num_classes=len(class_names)).to(device)
print(model)
손실함수와 옵티마이저 설정
# 1) 손실 함수 정의
# CrossEntropyLoss는 분류 문제에서 가장 널리 쓰이는 loss.
# 내부적으로 Softmax + Log + NLLLoss(음의 로그 우도 손실)을 한 번에 계산합니다.
criterion = nn.CrossEntropyLoss()
# 2) 옵티마이저 Adam 설정
optimizer = optim.Adam(
model.parameters(), # 모델의 모든 학습 가능한 파라미터
lr=0.001, # 학습률: 보통 SGD보다 작은 값으로 시작
betas=(0.9, 0.999), # (β1, β2) 과거 그래디언트 평균을 구할 때 쓰는 지수 가중치
eps=1e-08, # 수치 불안정성 방지를 위한 작은 상수
weight_decay=1e-4 # L2 규제(옵션): 과적합 방지
)
# 3) (선택) 스케줄러: 10 에폭마다 학습률을 0.1배로 줄임
scheduler = StepLR(optimizer, step_size=10, gamma=0.1)
print("설정 완료!")옵티마이저 변경 이유
- 논문 재현성 : 원본에서는 SGD with Momentum을 사용했으나, 현재 예제에서는 빠른 수렴과 실험 편의성을 위해 Adam을 선택했습니다.
학습 루프 작성
def train_model(model, dataloaders, criterion, optimizer, scheduler, num_epochs=10):
since = time.time()
# 전체 에폭 반복
for epoch in range(1, num_epochs+1):
print(f"\n=== Epoch {epoch}/{num_epochs} ===")
# Train / Test 두 단계로 나눠서 처리
for phase in ['train', 'test']:
if phase == 'train':
model.train() # 학습 모드 (Dropout, BatchNorm 활성)
else:
model.eval() # 평가 모드 (Dropout, BatchNorm 비활성)
running_loss = 0.0
running_corrects = 0
# 배치 단위로 데이터 가져오기
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad() # 이전 배치의 gradient 초기화
# 순전파(forward)
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs) # 모델 예측
_, preds = torch.max(outputs, 1) # 가장 높은 점수 클래스 선택
loss = criterion(outputs, labels) # 손실 계산
# 학습 단계일 때만 역전파
if phase == 'train':
loss.backward() # gradient 계산
optimizer.step() # 파라미터 업데이트
# 통계 누적
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
# 에폭 끝난 후 통계 계산
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print(f"{phase.capitalize()} Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}")
# 학습 모드 끝나면 스케줄러 스텝
if phase == 'train':
scheduler.step()
total_time = time.time() - since
print(f"\nTraining complete in {total_time//60:.0f}m {total_time%60:.0f}s")
# 실제 학습 실행
train_model(
model,
dataloaders,
criterion,
optimizer,
scheduler,
num_epochs=10
)# 결과
=== Epoch 1/10 ===
Train Loss: 0.8163 Acc: 0.4724
Test Loss: 0.6903 Acc: 0.5182
=== Epoch 2/10 ===
Train Loss: 0.6833 Acc: 0.5184
Test Loss: 0.6322 Acc: 0.5547
=== Epoch 3/10 ===
Train Loss: 0.5826 Acc: 0.6893
Test Loss: 0.4432 Acc: 0.8248
=== Epoch 4/10 ===
Train Loss: 0.5230 Acc: 0.7812
Test Loss: 0.4866 Acc: 0.8248
=== Epoch 5/10 ===
Train Loss: 0.5071 Acc: 0.7665
Test Loss: 0.3267 Acc: 0.8832
=== Epoch 6/10 ===
Train Loss: 0.3998 Acc: 0.8217
Test Loss: 0.3245 Acc: 0.8905
=== Epoch 7/10 ===
Train Loss: 0.4125 Acc: 0.8107
Test Loss: 0.3769 Acc: 0.8467
=== Epoch 8/10 ===
Train Loss: 0.5042 Acc: 0.7868
Test Loss: 0.5413 Acc: 0.8029
=== Epoch 9/10 ===
Train Loss: 0.4376 Acc: 0.8051
Test Loss: 0.3190 Acc: 0.8540
=== Epoch 10/10 ===
Train Loss: 0.3661 Acc: 0.8474
Test Loss: 0.3232 Acc: 0.8686
Training complete in 2m 37s2. CPU vs GPU 성능 비교 실험
같은 모델, 데이터, 하이퍼파라미터로 device만 바꿔가며 학습 시간과 최종 정확도를 기록하고 그래프로 비교
하드웨어에 따른 성능 차이를 확인해본다.
문제 발견
Colab 런타임을 GPU 모드로 설정한 뒤 CPU와 GPU를 실행했더니
- GPU: 78초, 87.6%
- CPU: 352초, 75.2%
=> 학습 시간 차이는 예상했지만, CPU쪽 정확도도 같아야 할 텐데 왜 낮게 나왔을까?
원인 분석 및 가설 수립
1. 초기 가중치 불일치
run_experiment() 안에서 매번 AlexNetCustom() 을 호출하면 매 실험마다 모델 가중치가 랜덤하게 다시 초기화 되기 때문에
결과적으로 GPU 실험과 CPU 실험이 서로 다른 출발점에서 학습을 시작하게 돼 최종 정확도도 달라졌을 것이다.
2. 랜덤 요소 통제 미흡
DataLoader(shuffle=True) 와 RandomHorizontalFlip(), Dropout(p=0.5) 등 학습 과정 곳곳에 난수 기반 동작이 있어.
배치 순서, 증강 패턴, 드롭아웃 패턴이 모두 실험마다 달라졌을 것이다.
가설 : 난수 시드를 고정하고, 베이스 모델을 한 번만 초기화 한 뒤 복제본을 사용한다면 비슷한 정확도가 나올 것이다.
# 난수 시드 고정
import random, numpy as np, torch
def set_seed(seed=123):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
set_seed(123) # 실험 전 단 한 번만 호출# 베이스 모델 한 번만 초기화 -> 복제본 사용
# 1) 시드 고정 후 베이스 모델 생성
base_model = AlexNetCustom(num_classes=2)
# 2) 매 실험 동일 가중치 복제
import copy
def run_experiment(device, num_epochs=5):
model = copy.deepcopy(base_model).to(device)
# ...optimizer, train_model 호출 등 동일...# DataLoader 난수 제어
g = torch.Generator()
g.manual_seed(123)
train_loader = DataLoader(
train_dataset,
batch_size=32,
shuffle=True,
generator=g
)
+ 데이터 증강·드롭아웃 시드 동기화 : torch.manual_seed(123) 를 for epoch 앞에 둬서 매 에폭마다 동일한 증강/드롭아웃 패턴이 적용되도록 함.
재 실험 결과
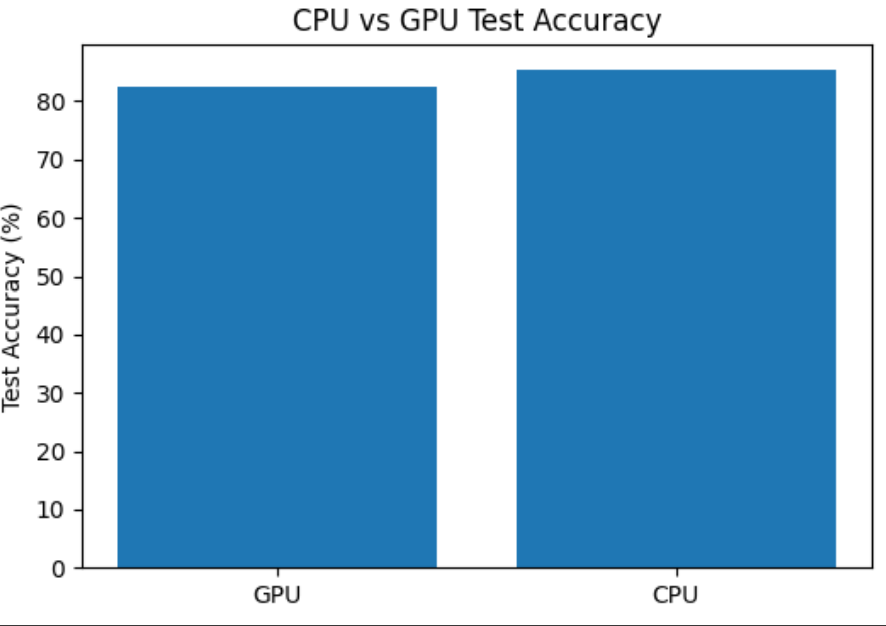
- GPU 학습시간 : 76.5초, 정확도 82.48%
- CPU 학습시간 : 350.1초, 정확도 85.40%
위 모든 통제를 적용하고 다시 실험한 결과, 최종 정확도가 거의 비슷하게 나오는 것을 확인
하드웨어 차이는 학습 시간에만 영향을 주고, 모델 성능 자체에는 직접적으로 영향을 주지 않을 것이다.
코드
# train_model() 내부에서 항상 전역변수 device로만 입출력을 옮기기 때문에, CPU 실험을 하려 해도
# 입력은 GPU 텐서가 되고, 모델 가중치는 CPU 텐서가 되어 타입이 달라져 버림
# 해결책: train_model에 사용할 장치를 인자로 넘기기
# train_model 정의를 바꿔, device를 파라미터로 받도록 수정
# 내부의 inputs.to(device) · labels.to(device)를 이 인자로 바꿔 줍니다
# run_experiment에서 CPU·GPU 각각의 디바이스 이름을 함께 넘겨 줍니다
def train_model(model, dataloaders, criterion, optimizer, scheduler,
num_epochs=10, device_name='cuda'):
since = time.time()
for epoch in range(1, num_epochs+1):
print(f"\n=== Epoch {epoch}/{num_epochs} ===")
for phase in ['train', 'test']:
if phase == 'train':
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0
for inputs, labels in dataloaders[phase]:
# ← 여기를 global device 대신 인자로 받은 device_name 사용
inputs = inputs.to(device_name)
labels = labels.to(device_name)
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
if phase == 'train':
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print(f"{phase.capitalize()} Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}")
if phase == 'train':
scheduler.step()
total_time = time.time() - since
print(f"\nTraining complete in {total_time//60:.0f}m {total_time%60:.0f}s")
return total_timeimport random, numpy as np, torch
def set_seed(seed=42):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
# 결정론적 연산을 위해 (속도 저하 감수)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
# 실험 전 한 번만 호출
set_seed(123)import copy
# 난수 시드 고정 후, 한 번만 베이스 모델 생성
base_model = AlexNetCustom(num_classes=len(class_names))
def run_experiment(device_name, num_epochs=10):
# ① 베이스 모델을 복제 → **동일한 초기 가중치** 사용
model_exp = copy.deepcopy(base_model).to(device_name)
# ② 옵티마이저·스케줄러·손실 함수 설정
optimizer_exp = optim.Adam(model_exp.parameters(), lr=0.001, weight_decay=1e-4)
scheduler_exp = StepLR(optimizer_exp, step_size=10, gamma=0.1)
criterion_exp = nn.CrossEntropyLoss()
# ③ 학습
elapsed = train_model(
model_exp,
dataloaders,
criterion_exp,
optimizer_exp,
scheduler_exp,
num_epochs=num_epochs,
device_name=device_name
)
# ④ 테스트 정확도 측정 (기존과 동일)
model_exp.eval()
correct = total = 0
with torch.no_grad():
for inputs, labels in dataloaders['test']:
inputs, labels = inputs.to(device_name), labels.to(device_name)
outputs = model_exp(inputs)
_, preds = torch.max(outputs, 1)
correct += (preds == labels).sum().item()
total += labels.size(0)
test_acc = correct / total
return elapsed, test_acc# GPU 사용 가능 여부 확인
print("CUDA available:", torch.cuda.is_available())
# 실험 실행 (에폭 수는 필요에 따라 조정)
time_gpu, acc_gpu = run_experiment('cuda' if torch.cuda.is_available() else 'cpu', num_epochs=5)
torch.cuda.empty_cache() # GPU 캐시 정리 (오류 방지)
time_cpu, acc_cpu = run_experiment('cpu', num_epochs=5)
# 결과 출력
print(f"\n=== CPU vs GPU 비교 결과 ===")
print(f"GPU 학습 시간: {time_gpu:.1f}s, 테스트 정확도: {acc_gpu*100:.2f}%")
print(f"CPU 학습 시간: {time_cpu:.1f}s, 테스트 정확도: {acc_cpu*100:.2f}%")CUDA available: True
=== Epoch 1/5 ===
Train Loss: 1.0218 Acc: 0.4982
Test Loss: 0.6924 Acc: 0.5182
=== Epoch 2/5 ===
Train Loss: 0.6905 Acc: 0.5441
Test Loss: 0.7415 Acc: 0.4818
=== Epoch 3/5 ===
Train Loss: 0.6935 Acc: 0.5147
Test Loss: 0.6550 Acc: 0.5255
=== Epoch 4/5 ===
Train Loss: 0.6482 Acc: 0.6140
Test Loss: 0.7083 Acc: 0.5182
=== Epoch 5/5 ===
Train Loss: 0.6087 Acc: 0.6636
Test Loss: 0.4394 Acc: 0.8248
Training complete in 1m 16s
=== Epoch 1/5 ===
Train Loss: 0.7428 Acc: 0.5184
Test Loss: 0.6667 Acc: 0.5328
=== Epoch 2/5 ===
Train Loss: 0.6699 Acc: 0.6048
Test Loss: 0.6850 Acc: 0.7518
=== Epoch 3/5 ===
Train Loss: 0.6275 Acc: 0.6581
Test Loss: 0.4089 Acc: 0.8321
=== Epoch 4/5 ===
Train Loss: 0.4656 Acc: 0.7684
Test Loss: 0.3207 Acc: 0.8467
=== Epoch 5/5 ===
Train Loss: 0.4604 Acc: 0.7904
Test Loss: 0.4101 Acc: 0.8540
Training complete in 5m 50s
=== CPU vs GPU 비교 결과 ===
GPU 학습 시간: 76.5s, 테스트 정확도: 82.48%
CPU 학습 시간: 350.1s, 테스트 정확도: 85.40%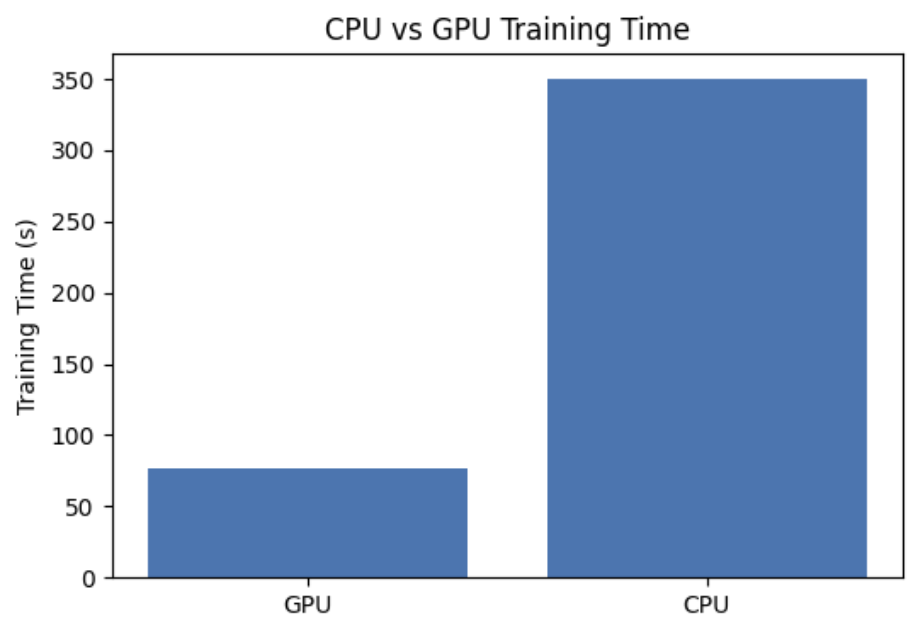
'논문 리뷰' 카테고리의 다른 글
| [논문 구현] Deep Residual Learning for Image Recognition (3) | 2025.08.08 |
|---|---|
| [논문 리뷰] Deep Residual Learning for Image Recognition 논문 과제 (1) | 2025.08.07 |
| AlexNet 논문에서 ReLU를 사용한 이유 직접 실험해보기, Sigmoid 함수의 정확도는 왜 이렇게 나왔을까? (3) | 2025.08.04 |
| ImageNet Classification with Deep Convolutional Neural Networks(2012) | AlexNet 논문 핵심 내용 요약 (4) | 2025.08.03 |
| 딥러닝 논문 가이드 _ 딥러닝 전체 (1) | 2025.08.03 |