1. 코드 목적 및 역할
약한 학습기(Decision Stump)를 여러 차례 순차적으로 학습시켜 강력한 앙상블 모델을 만드는 부스팅 기법을 실습.
+) 부스팅이란?
- 약한 학습기 (성능이 좋지 않은 간단한 모델)를 반복적으로 학습하여 강한 학습기(성능이 뛰어난 모델)를 만드는 앙상블 기법
AdaBoost와 Gradient Boosting의 차이점(가중치 업데이트 방식, 학습률 등)을 체험.
역할 :
- Iris 데이터 분할 → AdaBoost 학습→ 예측·평가
- GradientBoosting 학습→ 예측·평가 (정확도 비교)
- 마지막으로 결정트리(분류·회귀) 모델의 구조와 변수 중요도를 시각화
2. 필수 라이브러리
라이브러리 / 모듈 역할
| load_iris, train_test_split | 데이터셋 로드 및 학습/테스트 분할 |
| DecisionTreeClassifier | 기본 약한 학습기(stump) |
| AdaBoostClassifier, GradientBoostingClassifier | 부스팅 앙상블 구현 |
| accuracy_score | 분류 정확도 평가 |
| matplotlib.pyplot, plot_tree | 트리 구조 시각화 |
| pandas | DataFrame 생성 및 탐색 |
| DecisionTreeRegressor | 부스팅 후 회귀 나무 시각화 (Boston Housing) |
3. 주요 기능 흐름
1. 데이터 준비
- iris 데이터를 로드 -> 8:2 비율로 학습/테스트 분할
2. AdaBoostClassifier
- 약한 학습기 : 깊이 1인 결정 트리 (stump)
- n_estimators=50 만큼 순차 학습 -> 테스트 셋 예측 -> 정확도 계산
3. GradientBoostingClassifier
- n_estimators=365, learning_rate=0.1, max_depth=1
- 동일하게 학습 -> 예측 -> 정확도 계산
4. 트리 시각화 (분류기)
- 결정트리 분류기 (criterion=entropy, max_depth=3 등) 학습 후 plot_tree
5. get_info 함수
- 트리 내부 노드별 분할 기준, 불순도, 샘플 수, 예측 클래스 등 텍스트 정보 추출
6. 회귀 나무 시각화 (DecisionTreeRegressor)
- Boston Housing 데이터 로드 → 회귀 나무 학습→예측
- 변수 중요도 출력 → plot_tree 시각화
4. 코드
# boosting.py
# 부스팅
# 필수 라이브러리 import
from sklearn.datasets import load_iris # 붓꽃 데이터 불러오기
from sklearn.model_selection import train_test_split # 학습/테스트 분리 함수
from sklearn.tree import DecisionTreeClassifier # 의사결정나무 알고리즘을 분류 문제에 사용하는 클래스
from sklearn.ensemble import AdaBoostClassifier, GradientBoostingClassifier # 부스팅 기반 분류 알고리즘
from sklearn.metrics import accuracy_score #정확도 게산 함수
# iris 데이터셋
iris = load_iris()
X = iris.data # 독립변수(특징값) 담기 : 꽃받침, 꽃잎의 길이/너비
y = iris.target # 종속변수 (레이블) 담기 : 품종 (Setosa(0), Versicolor(1), Virginica(2))
# train/test 분리 (20%를 테스트로 분할)
X_train, X_test, y_train, y_test = \
train_test_split(X, y, test_size=0.2, random_state=42)
# AdaBoosting (Adaptive Boosting)
ada = AdaBoostClassifier( # 모델 객체 생성
# 기본분류기 (기본값이 DecisionTreeClassifier), max_depth:트리 깊이
# AdaBoost 기반 모델로 깊이가 1인 간단한 의사결정 나무 (Stump) 사용
# 트리의 깊이를 1로 제한하면 과적합을 방지하고 빠르게 학습 가능함.
estimator = DecisionTreeClassifier(max_depth=1),
# 부스팅 수행할 기본분류기 개수 : 약한 학습기 50개를 반복적으로 학습하여 강한 분류기를 만든다.
n_estimators = 50
)
# 모델 학습 : 생성한 AdaBoost 모델에 학습 데이터를 적용하여 훈련을 진행한다.
ada.fit(X_train, y_train)
# 예측값 : 훈련된 AdaBoost 모델을 사용하여 테스트 데이터로 예측을 진행한다.
ada_pred = ada.predict(X_test)
print(ada_pred) # [1 0 2 1 1 0 1 2 2 1 1 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0]
# 정확도 : 예측결과와 실제 결과를 비교해 정확도를 계산한다.
ada_acc = accuracy_score(y_test, ada_pred)
print(ada_acc) # 0.9333333333333333
## Gradient Boosting
gb = GradientBoostingClassifier( # Gradient Boosting 모델 객체를 생성
n_estimators = 365, # 부스팅을 수행할 분류기의 개수, 기본값 100 (약한 학습기=트리를 반복적으로 생생해 성능을 높임)
# 학습률, 기본값 0.1, 학습률이 작을수록 모델이 안정적이고 과적합이 줄어듬 (너무 작으면 학습이 느려지고, 크면 과적합 위험 커짐)
learning_rate = 0.1, #각 트리가 이전 트리의 오류를 수정하는 정도를 조정한다.
max_depth = 1 # 트리 최대 깊이, 기본값 3
)
# 모델 학습
gb.fit(X_train, y_train)
# 예측값
gb_pred = gb.predict(X_test)
print(gb_pred) # [1 0 2 1 1 0 1 2 2 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0]
# AdaBoost와 살짝 다름
# 정확도
gb_acc = accuracy_score(y_test, gb_pred)
print('정확도: ', gb_acc) #정확도: 0.9666666666666667
# 트리 시각화
# 시각화 라이브러리
import matplotlib.pyplot as plt # 데이터 시각화 라이브러리
from sklearn.tree import plot_tree #결정트리를 시각화 하는 함수
import pandas as pd # 데이터를 테이블 형태로 관리하는 라이브러리
# 데이터 로딩
iris = load_iris()
X = iris.data
y = iris.target
# train / test 분리
X_train, X_test, y_train, y_test = \
train_test_split(X, y, test_size=0.2, random_state=42)
# 데이터프레임
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df.info() # 150개 데이터 확인
# iris.target: [0, 0, 0, …, 2, 2, 2] 형태의 정수 배열
# iris.target_names: ['setosa', 'versicolor', 'virginica'] 문자열 배열
# list comprehension 동작
# for x in iris.target:
# iris.target_names[x] 를 꺼내서 리스트로 만든 뒤
# df['label'] 컬럼에 할당
# label 생성 (시각화를 위해서 함)
df['label'] = [iris.target_names[x] for x in iris.target]
# 독립변수 / 종속변수
X = df.drop('label', axis=1)
y = df['label']
# 의사결정나무분류기 생성
clf = DecisionTreeClassifier(
criterion = 'entropy', # 불순도 측정 기준으로 entropy를 사용한다.
# 결정트리가 각 노드를 분할할 때 어떤 기준으로 분할의 좋고 나쁨을 평가할지 정하는 파라미터
# gini : 지니 불순도 (기본)
# entropy : 엔트로피 최소화 : 정보 이득을 최대화 하도록 분할을 선택함
splitter = 'best', # 한 노드에서 어떤 특징과 임계값을 골라 분할할지를 결정하는 방식
# best : 모든 가능한 피처 x 임계값 조합을 전부 평가해서 "가장 불순도가 크게 감소"하는 분할을 선택 (정확도 측면에서 유리하지만, 큰 데이터셋에선 계산 비용이 커질 수 있다)
# random : 무작위로 선택한 일부 조합 중에서 최선인 분할을 선택 -> 학습 속도가 조금 빨라지고, 약간의 랜덤성을 줘서 과적합을 완화할 수 있음
max_depth = 3,
min_samples_leaf = 5 #최소 5개의 데이터가 한 리프 노드에 존재하도록 설정 (과적합 방지 목적)
)
# 모델 학습
clf.fit(X, y)
# 예측값 출력
print(clf.predict(X)[:3]) # setosa로 예측 : [np.str_('setosa') np.str_('setosa') np.str_('setosa')]
# 독립변수 중요도 출력
for i, column in enumerate(X.columns):
print(f'{column} 중요도 : {clf.feature_importances_[i]}')
'''
sepal length (cm) 중요도 : 0.0
sepal width (cm) 중요도 : 0.0
petal length (cm) 중요도 : 0.6881645055774848
petal width (cm) 중요도 : 0.3118354944225151
'''
# 시각화
plt.figure(figsize=(12, 8))
plot_tree(clf, feature_names=X.columns, class_names=clf.classes_)
plt.show()
# clf 정보 확인 함수
import numpy as np # 수학적 계산 및 배열 연산을 위한 라이브러리
def get_info(dt_model, tree_type='clf'): # 학습된 의사결정나무의 모든 노드 정보를 하나씩 상세하게 출력해주는 것
# 매개변수 : dt_model: 학습된 의사결정나무 모델 객체 (Classifier 또는 Regressor)
# tree_type: 'clf'(분류) 또는 'reg'(회귀)를 지정하여 출력 방식 결정 (기본값은 분류용 clf)
tree = dt_model.tree_ # 학습된 의사결정나무에서 내부적으로 저장된 트리 구조에 접근한다.
criterion = dt_model.get_params()['criterion'] # 분할에 사용된 기준을 추출함
# 트리 유형이 유효한지 확인
# assert : 주어진 조건이 참이 아니면 AssertionError를 발생시킴 (디버깅용으로 사용)
assert tree_type in ['clf', 'reg']
# 트리의 노드 수 전체를 가져옴 (분할노드와 리프노드를 포함)
num_node = tree.node_count
# 노드 정보를 저장할 리스트
info = []
# 트리의 각 노드 반복
for i in range(num_node):
# 각 노드의 정보를 저장할 딕셔너리
temp_di = dict()
# 현재 노드가 분할을 나타내는지 확인
if tree.threshold[i] != -2: # -2 : leaf node
# 분할에 사용된 특성과 임계값 저장
split_feature = tree.feature[i]
split_thres = tree.threshold[i]
# 분할 질문
temp_di['question'] = f'{split_feature} <= {split_thres:.3f}'
# 불순도와 노드에 포함된 샘플 수
impurity = tree.impurity[i]
sample = tree.n_node_samples[i]
# 불순도와 샘플 수 저장
temp_di['impurity'] = f'{criterion} = {impurity:.3f}'
temp_di['sample'] = sample
# 예측된 값(회귀), 클래스 확률(분류)
value = tree.value[i]
temp_di['value'] = value
# 분류 트리의 경우 예측된 클래스 레이블 저장
if tree_type == 'clf':
classes = dt_model.classes_
idx = np.argmax(value)
temp_di['class'] = classes[idx]
info.append(temp_di)
return info
# 함수 실행 : clf(분류트리)에 대해, 각 내부 노드의 질문, 불순도, 샘플수 예측 클래스 정보를 출력
print(get_info(clf))
# [{'question': '2 <= 2.450', 'impurity': 'entropy = 1.585', 'sample': np.int64(150), 'value': array([[0.33333333, 0.33333333, 0.33333333]]), 'class': np.str_('setosa')}, {}, {'question': '3 <= 1.750', 'impurity': 'entropy = 1.000', 'sample': np.int64(100), 'value': array([[0. , 0.5, 0.5]]), 'class': np.str_('versicolor')}, {'question': '2 <= 4.950', 'impurity': 'entropy = 0.445', 'sample': np.int64(54), 'value': array([[0. , 0.90740741, 0.09259259]]), 'class': np.str_('versicolor')}, {}, {}, {'question': '2 <= 4.950', 'impurity': 'entropy = 0.151', 'sample': np.int64(46), 'value': array([[0. , 0.02173913, 0.97826087]]), 'class': np.str_('virginica')}, {}, {}]
# Gradient Boosting 시각화
gb = GradientBoostingClassifier(
n_estimators = 120,
learning_rate = 0.1,
max_depth = 1
)
gb.fit(X_train, y_train)
first = gb.estimators_[0][0]
plt.figure(figsize=(8, 5))
plot_tree(first, filled=True, feature_names=iris.feature_names)
plt.show()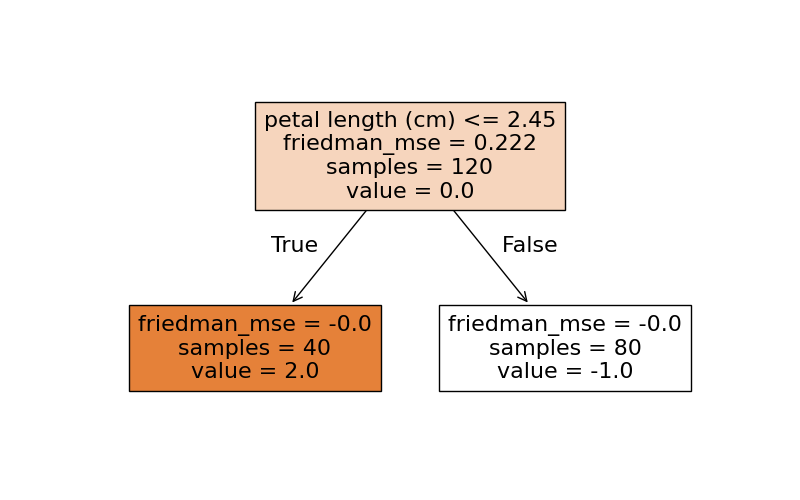
# 회귀나무 (DecisionTreeRegressor)
# 보스턴 주택가격 데이터
from sklearn import datasets
boston = datasets.fetch_openml(
'boston',
version = 1,
as_frame = True
)
# 데이터프레임
df = boston.frame
# 독립변수 / 종속변수 분리
X = df.drop('MEDV', axis=1) # 중간 주택가격 제외하고
y = df['MEDV']
# DecitionTreeRegressor
from sklearn.tree import DecisionTreeRegressor
reg = DecisionTreeRegressor(
criterion = 'squared_error',
splitter = 'best',
max_depth = 3,
min_samples_leaf = 10,
random_state = 100
)
# 학습
reg.fit(X, y)
# 예측값
print(reg.predict(X)[:3])
# 변수 중요도
for i, column in enumerate(X.columns):
print(f'{column} 중요도 : {reg.feature_importances_[i]}')
# 시각화
plt.figure(figsize=(15, 12))
plot_tree(reg, feature_names=X.columns)
plt.show()[22.6506383 22.6506383 35.24782609]
CRIM 중요도 : 0.03439671315633016
ZN 중요도 : 0.0
INDUS 중요도 : 0.0
CHAS 중요도 : 0.0
NOX 중요도 : 0.0
RM 중요도 : 0.6777780289645137
AGE 중요도 : 0.0
DIS 중요도 : 0.0
RAD 중요도 : 0.0
TAX 중요도 : 0.0
PTRATIO 중요도 : 0.008594584926950963
B 중요도 : 0.0
LSTAT 중요도 : 0.2792306729522052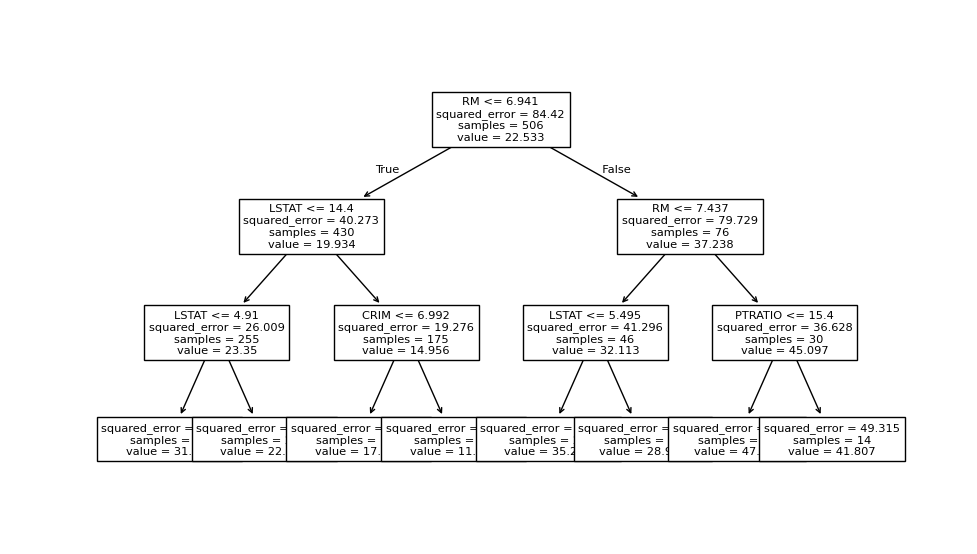
< 인사이트 >
1) AdaBoost vs GBDT 비교
- AdaBoost는 오분류 샘플에 가중치를 높여 순차 학습 -> 약한 학습기 여러 개 결합
- Gradient Boosting은 이전 모델의 잔차(residual)를 다음 모델이 보정 -> 학습률로 안정성 제어
2) 트리 모델 해부
- get_info로 각 분할 기준·불순도·샘플 수·예측 클래스를 텍스트로 확인
- plot_tree로 시각화하여 “어떤 특성이, 어떤 임계값으로 분할됐는지” 파악
3) 하이퍼파리미터 트레이드 오프
- n_estimators↑ → 표현력↑ vs 과적합↑
- learning_rate↓ → 안정성↑ vs 학습 속도↓
- max_depth↓ → 복잡도↓ → 과적합 완화
* 성능 vs 해석성 균형
- 부스팅은 단일 트리보다 정확도 높음. but 트리 수가 늘며 해석 난이도 높음
* 과적합 제어 전략
- 낮은 학습률 + 얕은 트리 조합이 검증 성능 안정성을 보장
* 데이터 특성 파악
- get_info를 통해 자주 분할된 피처를 보면, 데이터에서 핵심 패턴이 뭔지 이해
'Data Analysis Study' 카테고리의 다른 글
| CNN을 활용한 CIFAR-10 이미지 분류 분석 (1) | 2025.07.21 |
|---|---|
| 딥러닝 알고리즘 (Deep Learning Algorithms) 총정리 (0) | 2025.07.21 |
| 앙상블_소프트 보팅(VotingClassifier)을 통한 예측 수행 (1) | 2025.07.21 |
| 앙상블(Ensemble) 기법 개념 및 종류 정리 (0) | 2025.07.20 |
| 최적화 함수 (Optimizer)의 차이 시각적 이해 (0) | 2025.07.20 |