서울시의 공공 자전거 대여 서비스인 "따릉이"의 대여 수요를 예측하는 문제에 사용되는 데이터셋.
특정 시간대와 날씨, 요일, 공휴일 여부, 기온, 습도 등 다양한 데이터를 활용해 자전거 대여 수요를 예측
데이터셋 컬럼
Date : 연월일
Rented Bike count - 매 시간마다 대여한 자전거 수
Hour - 하루 중 시간
Temperature - 온도
Humidity - 습도 %
Windspeed - 풍속 m/s
Visibility - 가시거리 m
Dew point temperature - 이슬점 온도
Solar radiation - 태양 복사 MJ/m2
Rainfall - 강우량 mm
Snowfall - 적설량 cm
Seasons - 겨울, 봄, 여름, 가을
Holiday - 휴일/휴일 없음
Functional Day - 운영되지 않았던 날, 정상적으로 운영된 날
데이터 전처리 및 탐색적 데이터 분석 (EDA)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
bike_df = pd.read_csv('/SeoulBikeData.csv', encoding='CP949')
bike_df※ CP949
Microsoft Windows의 한국어 문자 인코딩입니다.
EUC-KR을 확장한 형태로, 더 많은 한국어 문자(한자, 확장 문자 등)를 지원합니다.
주로 Windows 환경에서 저장된 한글 파일에서 사용됩니다.bike_df.info()
===================
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 8760 entries, 0 to 8759
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Date 8760 non-null object
1 Rented Bike Count 8760 non-null int64
2 Hour 8760 non-null int64
3 Temperature(캜) 8760 non-null float64
4 Humidity(%) 8760 non-null int64
5 Wind speed (m/s) 8760 non-null float64
6 Visibility (10m) 8760 non-null int64
7 Dew point temperature(캜) 8760 non-null float64
8 Solar Radiation (MJ/m2) 8760 non-null float64
9 Rainfall(mm) 8760 non-null float64
10 Snowfall (cm) 8760 non-null float64
11 Seasons 8760 non-null object
12 Holiday 8760 non-null object
13 Functioning Day 8760 non-null object
dtypes: float64(6), int64(4), object(4)
memory usage: 958.3+ KB
bike_df.describe()
bike_df.columns
=======================
Index(['Date', 'Rented Bike Count', 'Hour', 'Temperature(캜)', 'Humidity(%)',
'Wind speed (m/s)', 'Visibility (10m)', 'Dew point temperature(캜)',
'Solar Radiation (MJ/m2)', 'Rainfall(mm)', 'Snowfall (cm)', 'Seasons',
'Holiday', 'Functioning Day'],
dtype='object')
# 컬럼명 재정의
bike_df.columns = ['Date', 'Rented Bike Count', 'Hour', 'Temperature', 'Humidity',
'Wind speed', 'Visibility', 'Dew point temperature',
'Solar Radiation', 'Rainfall', 'Snowfall', 'Seasons',
'Holiday', 'Functioning Day']
# scatterplot으로 상관관계 시각화
# 온도와 자전거 대여 수
sns.scatterplot(x='Temperature', y='Rented Bike Count', data=bike_df, alpha=0.3, color='darkviolet')
# 풍속과 자전거 대여 수
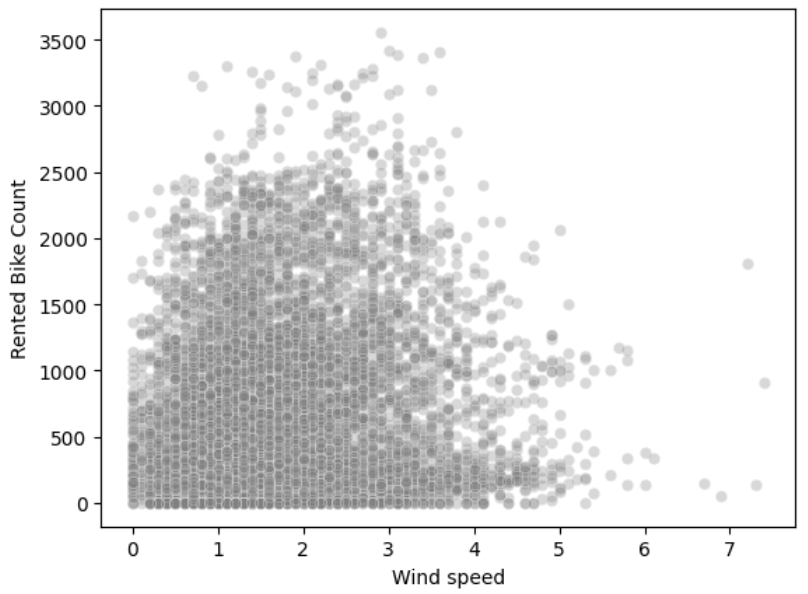
sns.scatterplot(x='Wind speed', y='Rented Bike Count', data=bike_df, alpha=0.3, color='gray')
# 가시거리와 자전거 대여 수 (숫자가 클수록 멀리서도 보임)
sns.scatterplot(x='Visibility', y='Rented Bike Count', data=bike_df, alpha=0.3, color='green')

# 날짜 Object type으로 되어있어서 datetime으로 바꾸고, format 맞춰주기
bike_df['Date'] = pd.to_datetime(bike_df['Date'], format='%d/%m/%Y')
bike_df.info()# 파생 변수 생성
bike_df['year'] = bike_df['Date'].dt.year
bike_df['month'] = bike_df['Date'].dt.month
bike_df['day'] = bike_df['Date'].dt.day
bike_df.head()
# 시계열 대여 수 시각화
plt.figure(figsize=(14, 4))
sns.lineplot(x='Date', y='Rented Bike Count', data=bike_df)
plt.xticks(rotation=45)
plt.show()
# Hour(0~23) 값을 네 개의 구간으로 나눠서, 각 시간대에 대응하는 이름(‘Dawn’, ‘Morning’, ‘Afternoon’, ‘Evening’)을 새 컬럼 TimeOfDay 에 지정
bike_df['TimeOfDay'] = pd.cut(bike_df['Hour'],
bins=[0, 5, 11, 17, 23],
labels=['Dawn', 'Morning', 'Afternoon', 'Evening'],
include_lowest=True) # 처음 시작 값은 포함시켜라* pd.cut()
pd.cut()은 숫자 데이터를 구간(bins)으로 나눠 범주형 데이터로 변환하는 데 사용된다.
주로 연속형 데이터를 특정 범주로 분류할 때 사용된다.
bins : 숫자 데이터를 나눌 경계값(구간)

sns.barplot(x='Functioning Day', y='Rented Bike Count', data=bike_df)
* barplot의 bar 역할
- 신뢰구간(CI) : 평균값이 속할 것으로 예상되는 값의 범위 (막대 위의 검은 선)
- 바 그래프에서 신뢰구간 : 검은색 심지로 나타낸다
- 신뢰구간이 좁다 : 평균값에 대한 확신이 높다
- 신뢰구간이 넓다 : 평균값에 대한 확신이 낮고 데이터가 흩어져 있다.
=> 위 그래프는 평균 대여량 추정치가 꽤 정확하다 라는 뜻으로 해석할 수 있다.
즉 운행일 데이터가 충분히 많고, 분산도 크지 않아서, 평균이 이 정도 범위 안에 잇을 것이다. 라고 확신할 수 있을 것이다!
라고 확신할 수 있는 폭이 좁게 계산된 것
bike_df['Functioning Day'].value_counts()
bike_df = pd.get_dummies(bike_df, columns=bike_df.select_dtypes(exclude=['number']).columns.tolist(), drop_first=True)
# drop_first=True : 원핫인코딩된 첫 번째 컬럼 수를 drop해서 피쳐 수를 하나 줄이겠다. 이렇게 해도 모델이 이해하는 데 전혀 문제 되지 않음
bike_df.head() #첫번째인 Dawn이 사라짐
# 모든 컬럼 간 상관관계 분석
correlation_matrix = bike_df.corr()
# 목표 변수와의 상관관계만 확인
target_corr = correlation_matrix['Rented Bike Count'].sort_values(ascending=False) # 내림차순
print(target_corr)
==========================
Rented Bike Count 1.000000
Temperature 0.538558
Hour 0.410257
Dew point temperature 0.379788
TimeOfDay_Evening 0.322978
Seasons_Summer 0.296549
Solar Radiation 0.261837
year 0.215162
Functioning Day_Yes 0.203943
Visibility 0.199280
month 0.133514
TimeOfDay_Afternoon 0.128639
Wind speed 0.121108
Holiday_No Holiday 0.072338
Seasons_Spring 0.022888
day 0.022291
TimeOfDay_Morning -0.081115
Rainfall -0.123074
Snowfall -0.141804
Humidity -0.199780
Seasons_Winter -0.424925
Name: Rented Bike Count, dtype: float64
* corr() 함수 : 데이터프레임의 숫자형 열 간의 상관관계를 계산하는 데 사용된다.
# 히트맵으로 확인해보기
plt.figure(figsize=(16, 12))
sns.heatmap(correlation_matrix, annot=True, fmt='.2f', cmap='Purples')
plt.title('Feature Correlation Heatmap')
plt.show()
본격 예측해보기
# 훈련/테스트 데이터 분할
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(bike_df.drop('Rented Bike Count', axis=1), bike_df['Rented Bike Count'], test_size=0.3, random_state=2025)
X_train.shape, y_train.shape # ((6132, 19), (6132,))
X_test.shape, y_test.shape # ((2628, 19), (2628,))사용 모델 : 결정 트리 (Decision Tree)
데이터를 기반으로 의사결정을 수행하는 트리 구조의 예측 모델
루트노드에서 시작해 각 노드는 특정 특성의 조건에 따라 가지로 분기됨
최종적으로 리프 노드에 도달해 예측 결과를 도출한다.
주로 분류와 회귀문제에 사용되며, 데이터의 패턴을 직관적으로 시각화할 수 있어 해석이 용이하다.
트리가 너무 깊어지면 과적합 문제가 발생할 수 있으므로 가지치기나 최대 깊이 설정 등으로 제어해야한다.
동작 원리
전체 데이터셋을 하나의 노드로 시작
최적의 특성과 분할 기준을 찾아 첫 번째 분할을 수행
분류 :
- 지니 불순도 : 노드 안에 있는 샘플들이 얼마나 섞여 있는지
- 엔트로피 : 노드 안의 정보(무질서도)가 얼마나 혼란스러운지
회귀 :
- 평균제곱오차 : MSE
- 절대평균오차 : MAE
각 하위 노드에 대해 위 단계를 반복
이 과정을 통해 트리는 여러 깊이로 성장한다. 모든 노드가 더 이상 나눌 수 없거나 특정 조건을 만족할 때까지 반복된다.
더 이상 분할이 불가능할 때 리프 노드가 생성된다.
분류 : 가장 많은 클래스가 있는 클래스를 예측값으로 사용
회귀 : 평균값을 예측값으로 사용
지니 불순도
한 노드에 있는 데이터의 순수도를 측정하는 지표.
한 노드에 있는 샘플들이 동일한 클래스에 속할 확률이 높을수록 지니 불순도는 낮아진다. 즉 노드가 얼마나 섞여 있는지를 나타낸다.
엔트로피
정보의 불확실성을 측정한다. 엔트로피가 높을수록 해당 노드에 있는 데이터는 더 섞여 있으며 예측하기 어렵다. 엔트로피는 데이터가 균등하게 분포될 때 최대값을 가짐
둘 다 노드가 얼마나 섞였나 측정하는 도구
실제 나무 만드는 과정에서 쓰기 편한 걸 고르면 된다.
- 섞여있을수록 값이 커진다 -> 더 분할할 필요가 있다.
- 한 쪽으로 치우칠수록 값이 작아진다 -> 이미 순수하니 멈춰도 된다.
from sklearn.tree import DecisionTreeRegressor
dtr = DecisionTreeRegressor(random_state=2025)
dtr.fit(X_train, y_train)
pred1 = dtr.predict(X_test)
sns.scatterplot(x=y_test, y=pred1)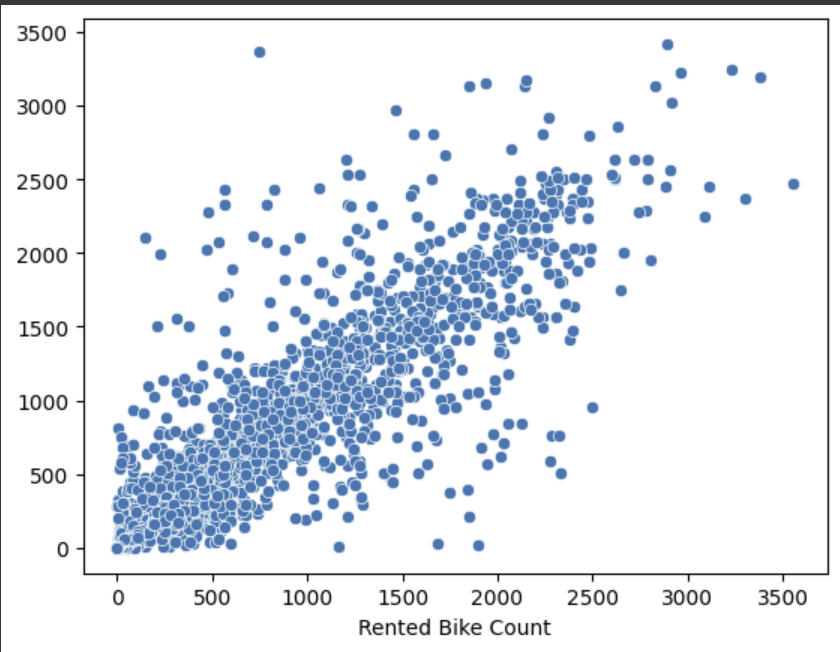
from sklearn.metrics import root_mean_squared_error
root_mean_squared_error(y_test, pred1)
# 313.7826116872321from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(X_train, y_train)
pred2 = lr.predict(X_test)
sns.scatterplot(x=y_test, y=pred2)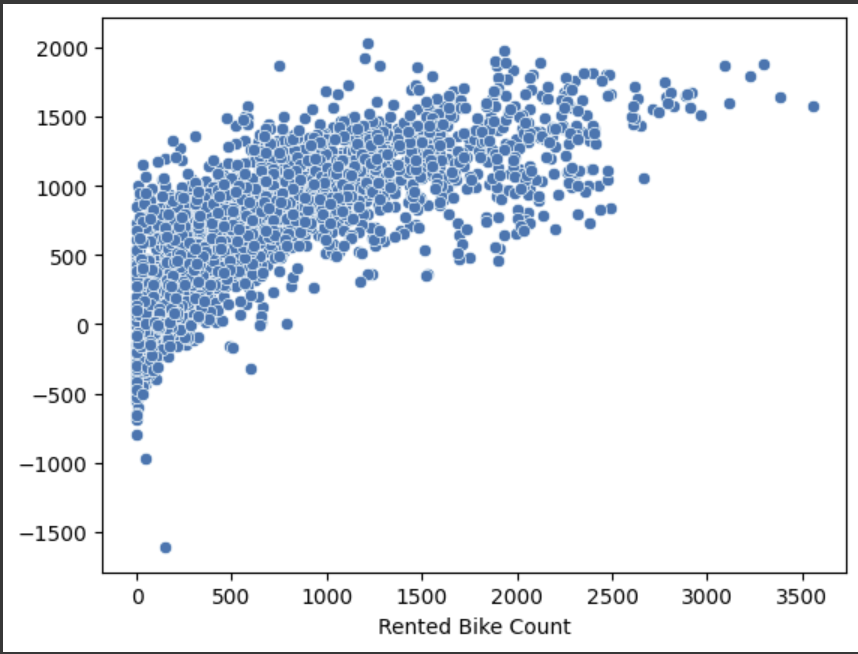
root_mean_squared_error(y_test, pred2)
# 420.7921510115953# 하이퍼 파라미터 적용
dtr = DecisionTreeRegressor(random_state=2025, max_depth=50, min_samples_leaf=30)
dtr.fit(X_train, y_train)
pred3 = dtr.predict(X_test)
root_mean_squared_error(y_test, pred3) # 293.44393572577195from sklearn.tree import plot_tree
plt.figure(figsize=(24, 12))
plot_tree(dtr, max_depth=5, fontsize=10, feature_names=X_train.columns)
plt.show()
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor(random_state=2025)
rf.fit(X_train, y_train)
pred4 = rf.predict(X_test)
root_mean_squared_error(y_test, pred4) #234.43573060707698print("설정된 트리 개수 (n_estimators):", rf.n_estimators)
print("실제로 학습된 트리 수 (len(estimators_)):", len(rf.estimators_))
=====================
설정된 트리 개수 (n_estimators): 100
실제로 학습된 트리 수 (len(estimators_)): 100rf.feature_importances_
array([0.2711775 , 0.32433855, 0.08286032, 0.01611289, 0.01597226,
0.09191418, 0.0396052 , 0.00075289, 0.00041153, 0.02197947,
0.01706343, 0.00169124, 0.00168268, 0.01549781, 0.0024369 ,
0.08600034, 0.00221501, 0.00480898, 0.00347884])feature_imp = pd.DataFrame({
'features': X_train.columns,
'importances': rf.feature_importances_
})feature_imp
top10 = feature_imp.sort_values('importances', ascending=False).head(10)
top10
plt.figure(figsize=(5, 10))
sns.barplot(x='importances', y='features', data=top10)
'Programming Study > Python & AI' 카테고리의 다른 글
| PyTorch 프레임워크 (4) | 2025.07.28 |
|---|---|
| 호텔 예약 수요 데이터셋, 고객 행동 예측, 수요 예측 실습 (0) | 2025.07.28 |
| 주택 임대료 예측 실습 (House Rent Prediction Dataset) (2) | 2025.07.25 |
| scikit-learn (사이킷런) _ Iris (붓꽃) 데이터 _ SVM (서포트 벡터 머신) (0) | 2025.07.25 |
| 커피 프랜차이즈의 입점 전략 분석 (6) | 2025.07.25 |