1. 코드의 목적 및 역할
이 스크립트(gridrandom_titanic.py)는 Kaggle의 Titanic 생존자 예측 데이터를 이용해 RandomForestClassifier를 기본 모델로 학습한 뒤, GridSearchCV vs RandomizedSearchCV로 하이퍼파라미터를 튜닝
각각의 최적 파라미터, CV 정확도, 테스트셋 정확도를 비교
튜닝 방식에 따른 시간·성능 트레이드오프를 체감
2. 필수 라이브러리 및 주요 기능
import pandas as pd #csv 로딩, 결측치 처리
from sklearn.model_selection import (
train_test_split, GridSearchCV, RandomizedSearchCV
) # 데이터 분할, 모델, 튜닝, 평가
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from scipy.stats import randint #RandomizedSearch용 이산분포
import matplotlib.pyplot as plt
3. 코드
1. 데이터 로드 및 전처리
df = pd.read_csv('assets/train.csv') #데이터 로드
# 1) 성별 → 숫자 (male: 0, female: 1)
df['Sex'] = df['Sex'].map({'male':0,'female':1})
# 2) Age 결측치 → 중앙값 (약 177개) 대체
df['Age'].fillna(df['Age'].median(), inplace=True)
# 3) Embarked 결측치(2개) → 최빈값 'S' → 숫자 매핑
df['Embarked'].fillna('S', inplace=True)
df['Embarked'] = df['Embarked'].map({'S':0,'C':1,'Q':2})
# 4) 사용할 피처
X = df[['Pclass','Sex','Age','SibSp','Parch','Fare','Embarked']]
y = df['Survived']
# 5) 80/20 분할 (random_state=42)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)- 결측치 처리 : Age 177개, Embarked 2개
- 피처 선택 : 총 7개 (범주형 3개, 수치형 4개)
2. 베이스라인 모델 학습 후 예측 및 정확도 출력
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print("베이스라인 정확도:", accuracy_score(y_test, y_pred))
# 정확도: 0.8268156424581006-> 아무 튜닝 없이도 기본 모델이 82.7%의 생존 예측 정확도를 보여줌
3. GridSearchCV 하이퍼파라미터 튜닝
param_grid = {
'n_estimators': [50,100,200],
'max_depth': [4,6,8,10],
'min_samples_split':[2,5],
'min_samples_leaf': [1,2]
}
grid_search = GridSearchCV(
estimator=model,
param_grid=param_grid,
cv=5,
scoring='accuracy',
n_jobs=-1
)
grid_search.fit(X_train, y_train)조합 수 : 3*4*2*2 = 48가지 CV5 -> 총 240회 학습
# 최적 하이퍼파라미터 및 정확도 출력
print("Best GridSearch Params:", grid_search.best_params_)
print("Best GridSearch Accuracy:", grid_search.best_score_)
-----------
Best GridSearch Params: {'max_depth': 6, 'min_samples_leaf': 1, 'min_samples_split': 2, 'n_estimators': 100}
Best GridSearch Accuracy: 0.832837584950261
4. RandomizedSearchCV 튜닝
4. RandomizedSearchCV 하이퍼파라미터 튜닝 / 최적 하이퍼파라미터 및 정확도 출력
param_dist = {
'n_estimators': randint(50, 300),
'max_depth': randint(4, 12),
'min_samples_split': randint(2, 10),
'min_samples_leaf': randint(1, 5)
}
random_search = RandomizedSearchCV(
estimator=model,
param_distributions=param_dist,
n_iter=20,
cv=5,
scoring='accuracy',
n_jobs=-1,
random_state=42
)
random_search.fit(X_train, y_train)
# 최적 하이퍼파라미터 및 정확도 출력
print("Best RandomSearch Params:", random_search.best_params_)
print("Best RandomSearch Accuracy:", random_search.best_score_)
----------------
Best RandomSearch Params: {'max_depth': 5, 'min_samples_leaf': 1, 'min_samples_split': 3, 'n_estimators': 133}
Best RandomSearch Accuracy: 0.8342361863488623
+ ) 시간도 비교해보기
import time
start = time.time()
grid_search.fit(X_train, y_train)
print("GridSearchCV 소요 시간:", time.time() - start, "초")
start = time.time()
random_search.fit(X_train, y_train)
print("RandomizedSearchCV 소요 시간:", time.time() - start, "초")
---
GridSearchCV 소요 시간: 4.3248207569122314 초
RandomizedSearchCV 소요 시간: 2.6333818435668945 초
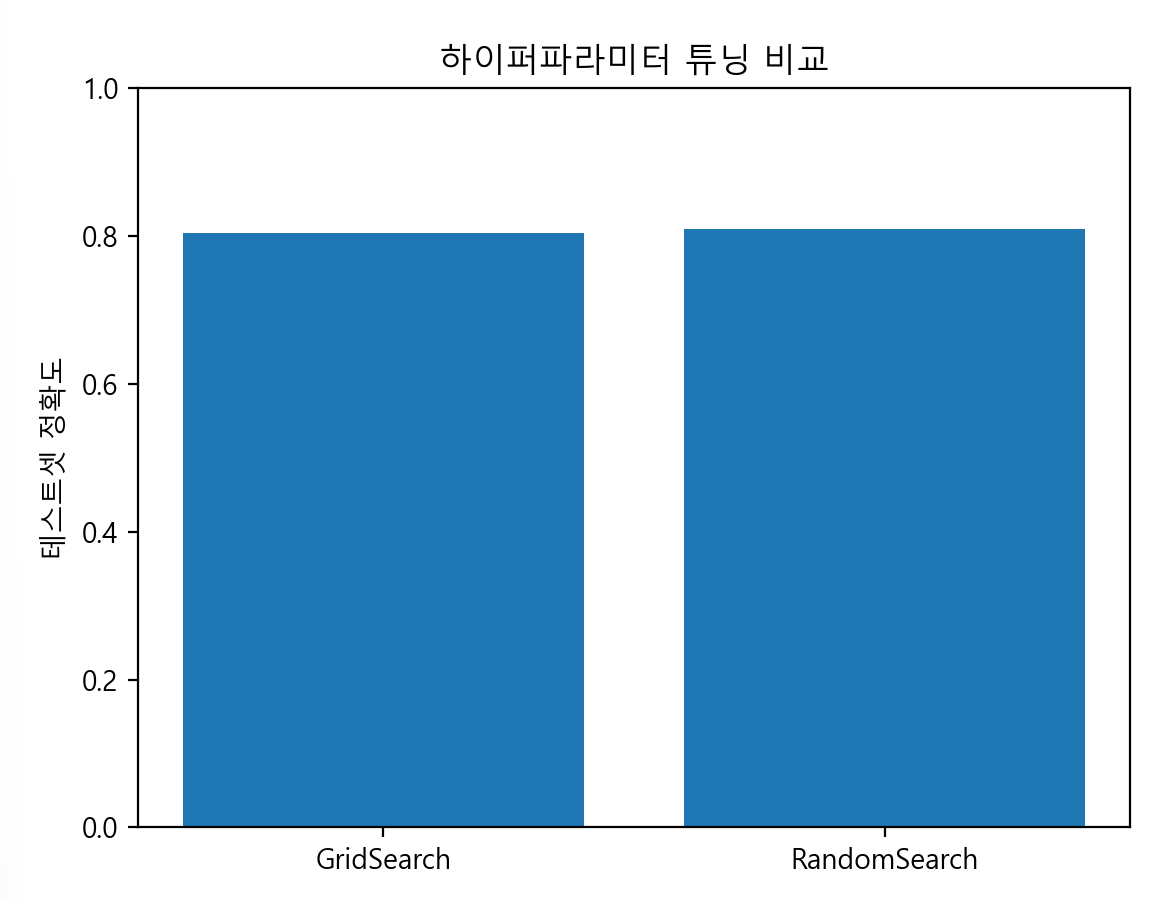
-> 실제 테스트 셋으로 했을 때 비교
grid_test_acc = accuracy_score(
y_test,
grid_search.best_estimator_.predict(X_test)
)
rand_test_acc = accuracy_score(
y_test,
random_search.best_estimator_.predict(X_test)
)
print("GridSearch Test Accuracy:", grid_test_acc)
print("RandomSearch Test Accuracy:", rand_test_acc)
---
GridSearch Test Accuracy: 0.8044692737430168
RandomSearch Test Accuracy: 0.8100558659217877
< 인사이트 >
1. 튜닝 전/후 실제 성능 비교
테스트에서 기본 모델(82.68%)이 GridSearch(80.45%), RandomSearch(81.01%)보다 더 높게 나옴.
-> 과도한 튜닝이 CV에서 점수를 올려도 실제 분할된 테스트 셋 일반화 성능에는 오히려 부정적일 수 있음 (과적합되었다고 볼 수 있다)
2. 시간 대비 효율
짧은 시간에 비슷하거나 더 나은 CV성능을 얻고 싶다면 RandomizedSearch가 유리
3. Default 파라미터가 이미 최적화된 상태일 수 있으므로, 튜닝 전후 테스트셋 성능을 반드시 체크
시간 대비 얻는 성능 향상이 미미하기 때문에 튜닝 예산을 줄이고 Defaut + 경량 튜닝 전략 추천
'Data Analysis Study' 카테고리의 다른 글
| TensorFlow의 핵심 개념과 사용법 (1) | 2025.07.10 |
|---|---|
| TensorFlow (텐서플로우) (1) | 2025.07.09 |
| XGBoostClassifier모델과 RandomizedSearch 하이퍼파라미터 튜닝 실습 (3) | 2025.07.09 |
| 랜덤포레스트모델과 GridSearch를 활용한 실습 (5) | 2025.07.09 |
| SVM (Support Vector Machine), XGBoost (Extreme Gradient Boosting), PCA (Principal Component Analysis), 하이퍼파라미터 튜닝, ROC Curve (6) | 2025.07.08 |