1. 손 글씨 숫자 데이터셋
0~9까지 숫자를 손글씨로 쓴 흑백 이미지로 구성되어있으며, 각 이미지는 8x8 픽셀 크기의 64차원 벡터로 표현된다.
각 픽셀 값은 0(흰색)에서 16(검은색)까지의 명암값을 가진다.
이 데이터는 총 1797개의 샘플로 이루어져 있다. 각 샘플에는 숫자 클래스가 레이블로 붙어있다.
주로 분류 알고리즘을 학습시키거나 데이터 시각화, 차원 축소 기법 등을 실험하는 데 사용된다.
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_digits.html
load_digits
Gallery examples: Recognizing hand-written digits Feature agglomeration Various Agglomerative Clustering on a 2D embedding of digits A demo of K-Means clustering on the handwritten digits data Sele...
scikit-learn.org
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from torch.utils.data import DataLoader # 핵심!!
digits = load_digits()
X_data = digits['data']
y_data = digits['target']
# 검정색 바탕에 흰 글씨로 되어 있을 것. 1797개 있다.
print(X_data) # 이미지 자체
print(y_data) #정답
=======================================================
[[ 0. 0. 5. ... 0. 0. 0.]
[ 0. 0. 0. ... 10. 0. 0.]
[ 0. 0. 0. ... 16. 9. 0.]
...
[ 0. 0. 1. ... 6. 0. 0.]
[ 0. 0. 2. ... 12. 0. 0.]
[ 0. 0. 10. ... 12. 1. 0.]]
[0 1 2 ... 8 9 8]from sklearn.datasets import load_digits : 사이킷런이 제공하는 손글씨 숫자 이미지 데이터셋을 불러온다.
from torch.utils.data import DataLoader : 파이토치의 Dataset 객체를 batch 단위로 묶고, 병렬로 데이터를 전처리, 로딩해주는 반복자(ierator)를 만들어준다.
DataLoader(
dataset, # torch.utils.data.Dataset 상속 클래스
batch_size=32, # 한 번에 읽어올 샘플 수
shuffle=True, # 에폭마다 데이터 순서를 섞을지 여부
num_workers=4 # 데이터를 미리 읽어올 프로세스(worker) 개수
)
* 사용 에시 : 넘파이 -> 텐서데이터셋 -> 데이터로더
axes.flatten()
다차원 배열 형태로 구성된 matplotlib의 서브플롯 배열을 1차원 배열로 변환하는 메서드
matplotlib에서 다수의 서브 플롯을 생성할 때, plt.subplots()는 2차원 배열 형태로 서브플롯 객체를 반환한다.
이 배열은 각 서브플롯을 접근하기 위해 행과 열의 인덱스를 사용해야하지만, flatten() 메서드를 사용하면 이 배열을 1차원으로 펼쳐서 각 서브 플롯을 단일 인덱스로 순회할 수 있게 된다.
fig, axes = plt.subplots(nrows=2, ncols=5, figsize=(14, 8))
# 2개의 행, 5개의 열, 전체 도화지 사이즈
# axes.flatten() : 한 줄로 평평하게 해주세요! 일단 한 열로 만들어주세요!
# 그래서 이중이 아니라 그냥 for문으로 돌릴 수 있음
for i, ax in enumerate(axes.flatten()):
# ax.imshow : 화면에 이미지를 보여줘라. reshape((8, 8)) : 1열로 되어있는 걸 8,8로 바꿔줘라.
ax.imshow(X_data[i].reshape((8, 8)), cmap='gray')
ax.set_title(y_data[i])
ax.axis('off')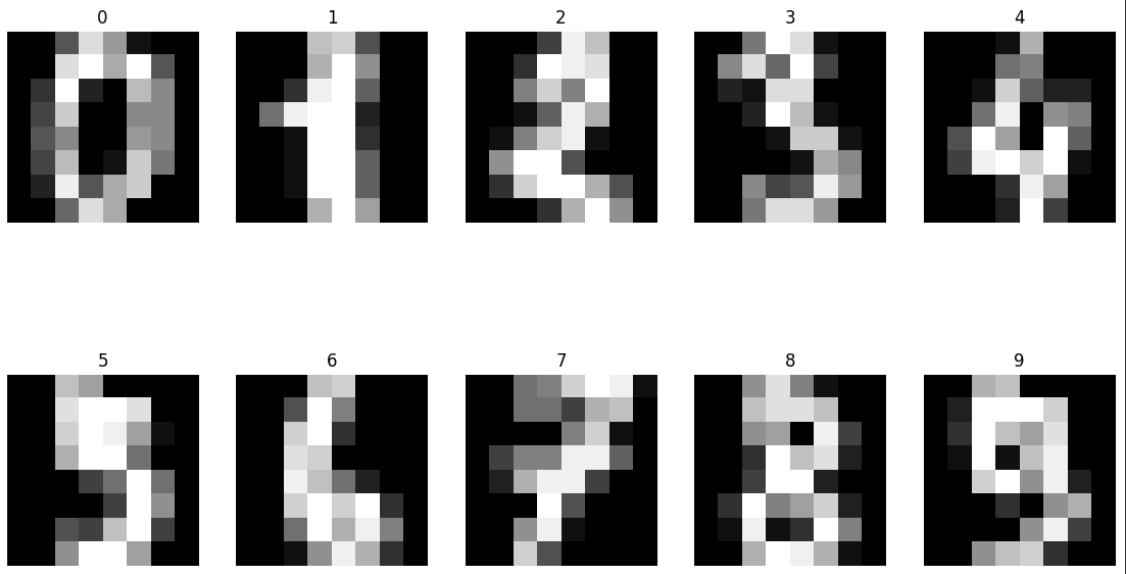
X_data = torch.FloatTensor(X_data)
y_data = torch.LongTensor(y_data)
print(X_data.shape) # torch.Size([1797, 64])
print(y_data.shape) # torch.Size([1797])
- x_data는 특징 값을 담고 있어서 연산에 실수가 필요하므로 FloatTensor로 변환한다
- y_data는 정답 레이블을 담고 있기 때문에 실수가 아니라 정수 형태, LongTensor여야 한다.
x_train, x_test, y_train, y_test = train_test_split(X_data, y_data, test_size=0.2, random_state=2025)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
=================================================
torch.Size([1437, 64]) torch.Size([1437])
torch.Size([360, 64]) torch.Size([360])
2. 데이터 로더
데이터셋을 효율적으로 관리하고, 모델 학습 과정에서 데이터를 쉽게 가져올 수 있도록 도와주는 도구
일반적으로 데이터 셋을 배치 단위로 나눠 모델에 제공하며,
데이터의 크기가 클 경우에도 메모리를 효율적으로 처리할 수 있도록 설계됨
데이터 증강, 셔플링, 병렬 처리와 같은 기능을 지원하여 학습 성능을 향상시키고, 모델 학습과 평가 시 일관된 데이터 제공방식을 유지
딥러닝 프레임 워크에서는 파이토치의 DataLoader나 TensorFlow의 tf.data같은 도구를 통해 쉽게 사용할 수 있다.
데이터로더의 주요 역할
1. 배치 처리 : 데이터를 지정된 크기의 배치로 나눠 모델에 제공
2. 셔플링 : 데이터 순서를 무작위로 섞어 과적합 방지
3. 병렬 처리 : num_workers 옵션을 통해 데이터를 병렬로 로드해 속도 향상
4. 반복처리 : 학습 epoch 동안 데이터를 자동으로 반복해서 제공
loader = DataLoader(
# 1. 데이터셋을 넣어줄건데, 리스트 형식으로 넣어주기.
# 튜플로 제공할건데, 이미지와 정답을 함께 제공할 것. "입력 : 정답" 쌍을 리스트로 제공
dataset=list(zip(x_train, y_train)),
# 2. 보통은 2의 n승. (1437개 / 64 = 22번...29개 )
batch_size=64, # 하나의 배치에 들어가는 개수
shuffle = True, # 매 에폭마다 데이터 순서를 무작위로 섞을 지 여부
drop_last=False # 배치 크기에 못 미치는 마지막 샘플을 버릴지 여부
)imgs, labels = next(iter(loader)) #이터레이터로 만들어주기 (반복문으로 쓸 수 있음)
# 64개 이미지, 64개 라벨 하나 빼줌
fig, axes = plt.subplots(nrows=8, ncols=8, figsize=(14, 14))
for ax, img, label in zip(axes.flatten(), imgs, labels):
ax.imshow(img.reshape((8, 8)), cmap='gray')
ax.set_title(str(label))
ax.axis('off')
model = nn.Sequential(
nn.Linear(64, 10) #64개를 입력받아서 10개(0부터 9까지 확률)를 내보내줘야함
)
# 다항 로지스틱 회귀이기 때문에 softmax를 loss함수에 껴주면 된다.
optimizer = optim.Adam(model.parameters(), lr=0.01)
미니배치 학습을 위해 에폭마다 전체 데이터 셋을 배치 단위로 나눠서 반복 수행하는 구조
epochs = 100
for epoch in range(epochs + 1):
sum_losses = 0
sum_accs = 0
# ──────── 배치 단위 반복 ────────
for x_batch, y_batch in loader:
# 1) 순전파(Forward): 이 배치에 대한 로짓 계산
y_pred = model(x_batch)
# 2) 손실 계산: 배치 단위 CrossEntropy
loss = nn.CrossEntropyLoss()(y_pred, y_batch)
# 3) 기울기 초기화 → 4) 역전파 → 5) 파라미터 업데이트
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 손실 누적
sum_losses += loss
# 예측 확률 계산 → 예측 클래스 인덱스 → 배치 정확도 계산
y_prob = nn.Softmax(dim=1)(y_pred)
y_pred_index = torch.argmax(y_prob, axis=1)
acc = (y_batch == y_pred_index).float().sum() \
/ len(y_batch) * 100
sum_accs += acc
# ────────────────────────────────
# 에폭 당 평균 손실·정확도 계산
avg_loss = sum_losses / len(loader)
avg_acc = sum_accs / len(loader)
print(f'Epoch {epoch:4d}/{epochs} '
f'Loss: {avg_loss:.6f} '
f'Accuracy: {avg_acc:.2f}%')
1. 바깥쪽 루프 (for epoch in range(...))
- 전체 데이터 셋을 몇 번 반복 학습할 지 정함
2. 안쪽 루프 (for x_batch, y_batch in loader)
- DataLoader가 만들어놓은 미니 배치 (64개 샘플 묶음)를 하나씩 꺼내서
- 순전파 > 손실 > 역전파 > 업데이트 과정을 배치 단위로 수행한다.
+ ) 이전 예제에서는 x_train 전체를 한 번에 모델에 넣었기 때문에 안쪽 루프가 필요 없었다. 지금은 x_train을 64개씩 잘게 나눠서 학습 하기 때문마다 에폭마다, 각 배치에 대해 반복해야 해서 이중 for문이 생김.
에폭 루프 (전체 반복 횟수)
└─ 배치 루프 (미니배치 단위 연산)
├ 순전파 → 손실 계산
├ 역전파 → 파라미터 업데이트
└ 손실·정확도 누적
└─ (배치 루프 끝) 평균 지표 계산 → 출력
plt.imshow(x_test[10].reshape((8, 8)), cmap='gray')
print(y_test[10]) # tensor(5)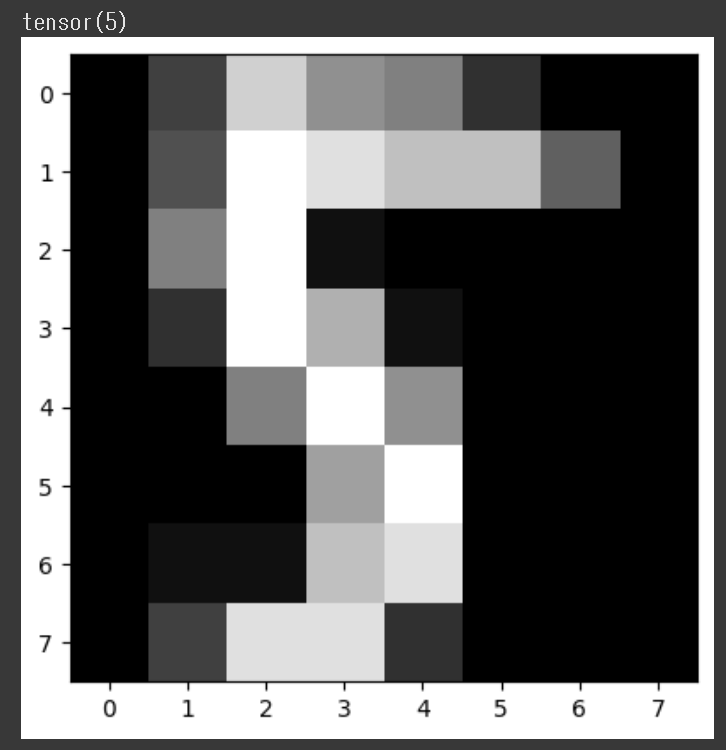
- 테스트 데이터 셋에서 11번째 샘플 (인덱스 10) 에 해당하는 1차원 벡터(길이 64인 것)를 꺼낸다.
그리고 8 x 8 ) 2차원 배열로 재배열 해준다.
흑백 영상으로 화면에 그려준다. imshow는 기본 컬러맵이기 때문에 cmap='gray'를 지정해야 흑백 이미지처럼 보인다.
y_test[10] : 위에 표시한 11번째 이미지의 실제 정답 레이블을 꺼낸다. # tensor(5)
# 학습된 모델을 x_test에 순전파로 집어 넣기
y_pred = model(x_test) # 테스트셋의 모든 샘플에 대해 로짓을 계산
y_pred[10] # 그 중 11번째 샘플에 대한 로짓 벡터를 꺼냄
=================================================================================
tensor([ -4.5748, -14.9358, -4.5453, -0.2196, -9.4613, 13.2823, -11.8678,
-0.2777, 2.1813, -8.1998], grad_fn=<SelectBackward0>)- 출력된 값은 각각 "이 샘플이 숫자 0일 점수, 1일 점수 ... 9일 점수) 순서로 10개의 raw score을 보여준다.
- 이 값들은 softmax 함수를 거치기 전 단계의 점수이기 때문에 가장 높은 값 (5)라고 볼 수 있음
# softmax 함수에 넣어주기
y_prob = nn.Softmax(1)(y_pred)
y_prob[10]
tensor([1.7570e-08, 5.5596e-13, 1.8096e-08, 1.3683e-06, 1.3261e-10, 9.9998e-01,
1.1952e-11, 1.2911e-06, 1.5097e-05, 4.6820e-10],
grad_fn=<SelectBackward0>)for i in range(10):
print(f'숫자 {i}일 확률: {y_prob[10][i]:.2f}')
=========================================================
숫자 0일 확률: 0.00
숫자 1일 확률: 0.00
숫자 2일 확률: 0.00
숫자 3일 확률: 0.00
숫자 4일 확률: 0.00
숫자 5일 확률: 1.00
숫자 6일 확률: 0.00
숫자 7일 확률: 0.00
숫자 8일 확률: 0.00
숫자 9일 확률: 0.00# 모델의 예측값과 실제 정답을 비교해서 전체 샘플 중 맞힌 비율 (정확도) 구하기
y_pred_index = torch.argmax(y_prob, axis=1) # 클래스별 예측 확률 텐서 (결국 집어 넣은 값의 예측값이 뭐냐)
accuracy = (y_test == y_pred_index).float().sum() / len(y_test) * 100
print(f'테스트 정확도는 {accuracy: .2f}% 입니다.')
- y_test == y_pred_index : 실제 레이블 y_test와 예측 클래스 인덱스를 요소별로 비교해서 같으면 True, 다르면 False인 Boolean 텐서를 만든다.
예 : (예: [1,2,3] == [1,0,3] → [True, False, True])
- .float() : True→1.0, False→0.0 으로 타입을 바꿔서 (y_test == y_pred_index).float()는 [1.0, 0.0, 1.0] 같은 식의 0·1 텐서가 된다.
- .sum() : 1.0들만 더해서 맞힌 샘플 수를 구한다.
- / len(y_test) : 전체 샘플 수로 나눠서, 맞힌 비율 을 구한다.
3. 데이터 증강 (Data Augentation)
학습 데이터를 인위적으로 변환해 데이터 셋의 다양성을 높이고 모델의 일반화 성능을 향상시키는 기법.
회전, 크기 조정, 반전, 블러링, 밝기 조정 등 다양한 변환을 적용해 원본 데이터로부터 새로운 데이터를 생성.
이를 통해 데이터 부족 문제를 완화. 모델이 특정 패턴에 과적합 되지 않도록 도와준다.
이미지나 음성 데이터와 같이 특징이 직관적인 데이터에서 효과적으로 활용됨. 증강된 데이터는 모델이 예측 대상의 다양한 변형에 대해 강하게 학습할 수 있도록 돕는다.
https://docs.pytorch.org/vision/0.9/transforms.html
torchvision.transforms — Torchvision master documentation
torchvision.transforms Transforms are common image transformations. They can be chained together using Compose. Additionally, there is the torchvision.transforms.functional module. Functional transforms give fine-grained control over the transformations. T
docs.pytorch.org
from torchvision import transforms # 데이터를 변환할 때 쓰는 모듈 (변환 기법들이 있음)
from torch.utils.data import TensorDataset # 텐서형을 데이터 셋으로 저장하거나, 변환할 수 있는 모듈 (직접)
from torch.utils.data import Dataset # 텐서랑 상관 없이 데이터 셋을 구축할 때 쓰이는 모듈X_train, X_test, y_train, y_test = train_test_split(X_data, y_data, test_size=0.2, random_state=2025)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
=====================================
torch.Size([1437, 64]) torch.Size([1437])
torch.Size([360, 64]) torch.Size([360])# 텐서 데이터 셋으로 묶어보기
train_dataset = TensorDataset(X_train, y_train)
test_dataset = TensorDataset(X_test, y_test)# 데이터 셋으로 만들어놓게 되면 데이터셋을 미니 배치 형식으로 묶어서 처리할 수 있는 로더에 집어넣기 편하다.
transform = transforms.Compose([
transforms.RandomRotation(10), # 무작위 회전
transforms.RandomAffine(0, shear=5, scale=(0.9, 1.1)), # 회전, 이미지 비틀기, 크기 조정
])- 데이터를 여러가지 방식으로 변형할 때 쓰는 모듈.
- Compose는 여러 개를 한 꺼번에 변형시킬 때 쓸 수 있음. 그래서 대괄호를 사용한다.
* transforms.Compose
# PyTorch Dataset을 상속해서 “원본 데이터 위에 원하는 변형(transform)을 적용”하는 커스텀 데이터셋
class AugmentedDataset(Dataset): #위에서 import 한 Dataset을 상속받아 만든다. (오버라이딩)
def __init__(self, dataset, transform): # 객체를 만들 때, dataset도 넣을 거고, 변형도 넣을거임
self.dataset = dataset
self.transform = transform
def __len__(self):
return len(self.dataset) # 데이터가 몇 개인지 알려주고 싶어
def __getitem__(self, idx):
x, y = self.dataset[idx] # 이미지와 라벨을 분할해서 넣어줄 것 (원래는 64짜리 1줄)
x = x.view(8, 8).unsqueeze(0) # 8x8 이미지를 가상으로 1채널로 변환 (1,8,8)
# unsqueeze : 0번에 차원 하나 늘려라.
x = self.transform(x) # 증강 적용
return x.flatten(), y # 다시 Flatten (다시 1열로 늘려달라)
# 객체 생성
augmented_train_dataset = AugmentedDataset(train_dataset, transform)목적: 원본 데이터를 건드리지 않고, 매번 꺼낼 때마다 실시간으로 이미지 형태로 변환하고 transform을 적용하려는 것
흐름 :
인덱스로 하나 뽑기 → 1D→2D 이미지 변환 → 채널 차원 추가 → 증강 적용 → 2D→1D로 다시 펴기 → (x, y) 반환장점 :
- 메모리 낭비 없이
- 한 줄의 코드로 데이터 증강과 전처리를 깔끔하게 분리할 수 있다.
class AugmentedDataset(Dataset):- torch.utils.data.Dataset을 상속해서,
- __len__과 __getitem__ 메소드를 오버라이드(재정의) 할 수 있게 해 준다.
def __init__(self, dataset, transform):
self.dataset = dataset
self.transform = transform- 생성자(__init__)에서 dataset(원본 (x, y) 쌍들이 들어 있는 리스트나 TensorDataset 등), transform(이미지 증강 함수나 torchvision.transforms 객체) 를 받아 내부에 저장해둠.
def __len__(self):
return len(self.dataset)- 파이썬 len() 호출 시, 데이터셋 크기를 돌려줌.
- DataLoader가 “몇 개의 샘플이 있나” 물을 때 쓰임
def __getitem__(self, idx):
x, y = self.dataset[idx] # 원본에서 (이미지 벡터, 레이블) 한 쌍 추출
x = x.view(8, 8).unsqueeze(0) # 1D 벡터(64) → 8×8 이미지로 reshape, 채널 차원 추가 ⇒ (1, 8, 8)
x = self.transform(x) # 지정된 증강(transform) 함수/객체 적용
return x.flatten(), y # 다시 1D(64)로 펴서 리턴, 레이블은 그대로
- view(8,8): 1×64짜리 벡터를 8×8짜리 2D 이미지로 재배열
- unsqueeze(0): “채널(Channel)” 차원을 하나 추가해서 (1, H, W) 형태로 맞춤
- self.transform(x): 예를 들어 랜덤 회전·자르기·색 보정 등 실시간 데이터 증강
- flatten(): 모델에 넣기 위해 다시 1D 벡터로 변환
augmented_train_dataset = AugmentedDataset(train_dataset, transform)
이렇게 객체를 생성해두면,
loader = DataLoader(augmented_train_dataset, batch_size=…, shuffle=…)이렇게 DataLoader에 바로 연결해 증강된 데이터를 배치 단위로 읽어올 수 있음.
len(augmented_train_dataset) # 1437train_loader = DataLoader(augmented_train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)- 학습 데이터는 데이터 증강 + 셔플 적용
imgs, labels = next(iter(train_loader))
fig, axes = plt.subplots(nrows=8, ncols=8, figsize=(14, 14))
#하나씩 뽑아서 iter로 만들어서 순서대로 배열한 다음에 64개씩 들어갈 것
for ax, img, label in zip(axes.flatten(), imgs, labels):
ax.imshow(img.reshape((8, 8)), cmap='gray')
ax.set_title(str(label))
ax.axis('off')
- 데이터 증강 효과를 넣었기 때문에 살짝 비틀어져 있는 것들도 있고, 벗어난 것들도 있다.
for images, labels in train_loader:
print(f"Image batch shape: {images.shape}")
print(f"Label batch shape: {labels.shape}")
break
=================================================
Image batch shape: torch.Size([64, 64])
Label batch shape: torch.Size([64])증강기법을 쓴 다음 다시 학습 시켜보기
# 모델 정의
model = nn.Sequential(
nn.Linear(64, 10) # 64차원 입력을 받아 10차원 로짓(클래스 점수)을 내보내는 한 줄짜리 완전연결층
)
# 옵티마이저 설정
optimizer = optim.Adam(model.parameters(), lr=0.01) # Adam 알고리즘 사용, 학습률 0.01로 파라미터 업데이트
epochs = 100
for epoch in range(epochs + 1): # 0부터 100까지 총 101회 반복
sum_losses = 0 # 한 에폭동안 누적된 손실 합을 기록할 변수
sum_accs = 0 # 한 에폭동안 누적된 정확도 합을 기록할 변수
for x_batch, y_batch in train_loader:
y_pred = model(x_batch) # 순전파: 배치(예:64개) → 로짓(64×10) 64개 넣어서 한 번에 예측
loss = nn.CrossEntropyLoss()(y_pred, y_batch) # 손실 계산은 CrossEntropy
optimizer.zero_grad() # 1. 이전 기울기 초기화
loss.backward() # 2. 역전파 : 기울기 계산
optimizer.step() # 3. 파라미터 업데이트
sum_losses = sum_losses + loss # 한 에폭동안 매 배치의 손실값을 다 더해준다.
# 예측 확률 및 클래스 변환 -> 배치 정확도 계산
y_prob = nn.Softmax(1)(y_pred) # 로짓 -> 확률
y_pred_index = torch.argmax(y_prob, axis=1) # 가장 확률 높은 클래스의 인덱스 뽑기
acc = (y_batch == y_pred_index).float().sum() / len(y_batch) * 100 # 정확도 계산
sum_accs = sum_accs + acc # 한 에포크 동안 매 배치의 정확도 다 더해줌
if epoch % 10 == 0:
avg_loss = sum_losses / len(loader) # 배치 수로 나눠 평균 손실
avg_acc = sum_accs / len(loader) # 배치 수로 나눠 평균 정확도
print(f'Epoch {epoch:4d}/{epochs} Loss: {avg_loss:.6f} Accuracy: {avg_acc:.2f}%')
< 전체 사이클 요약 >
for epoch in range:
초기화(sum_losses, sum_accs)
for each batch:
1) 순전파 → 로짓
2) 손실 계산
3) zero_grad → backward → step
4) 손실·정확도 누적
if (출력 주기):
평균 지표 계산 → 출력- 미니배치 학습을 통해 모델의 가중치가 조금씩 조정되고, 에폭이 지날수록 손실은 줄고 정확도는 올라가며 학습이 진행됨.
# 잘 맞추는 지 학인해보기!
plt.imshow(x_test[11].reshape((8, 8)), cmap='gray')
print(y_test[11])
y_pred = model(x_test) # 테스트를 다 넣었기 때문에,
y_pred[11] # 결과 중 11번만 보면 된다
======================================================================================================
tensor([-18.1495, -7.1540, -0.6443, 14.3158, -2.8968, -3.3383, -31.9708,
29.2582, -7.8698, 7.4571], grad_fn=<SelectBackward0>)
y_prob = nn.Softmax(1)(y_pred) #확률 뽑기
y_prob[11]
======================================================================================================
tensor([2.5768e-21, 1.5360e-16, 1.0316e-13, 3.2405e-07, 1.0846e-14, 6.9748e-15,
2.5621e-27, 1.0000e+00, 7.5080e-17, 3.4033e-10],
grad_fn=<SelectBackward0>)
for i in range(10):
print(f'숫자 {i}일 확률: {y_prob[11][i]:.2f}')
====================================================
숫자 0일 확률: 0.00
숫자 1일 확률: 0.00
숫자 2일 확률: 0.00
숫자 3일 확률: 0.00
숫자 4일 확률: 0.00
숫자 5일 확률: 0.00
숫자 6일 확률: 0.00
숫자 7일 확률: 1.00
숫자 8일 확률: 0.00
숫자 9일 확률: 0.00'Programming Study > Python & AI' 카테고리의 다른 글
| Multi-class Weather Dataset | 머신러닝 모델 학습 예제 (4) | 2025.08.05 |
|---|---|
| 퍼셉트론과 다층퍼셉트론, 활성화함수 (5) | 2025.08.04 |
| 파이토치로 구현한 논리회귀 (2) | 2025.08.03 |
| 파이토치로 구현한 선형회귀 (1) | 2025.07.29 |
| PyTorch 프레임워크 (4) | 2025.07.28 |