0. LSTM과 다른 시계열 모델의 차이란?
보통의 시계열 모델은 단기 기억만 가능하지만, LSTM은 장기 기억도 가능하다.
일반 시계열 모델 : 어제 비가 왔으니까 오늘도 비가 오겠지. => 가까운 과거만 보고 예측
LSTM : 작년 이맘 때 비가 많이 왔고, 3개월 전붜 비슷한 패턴이 보이니까 이번에도 비가 많이 올 듯?
즉, 복잡한 패턴을 잘 찾아내서, 날씨 예보, 주식 시장 예측, 방문객 수 예측 등에 많이 사용된다.
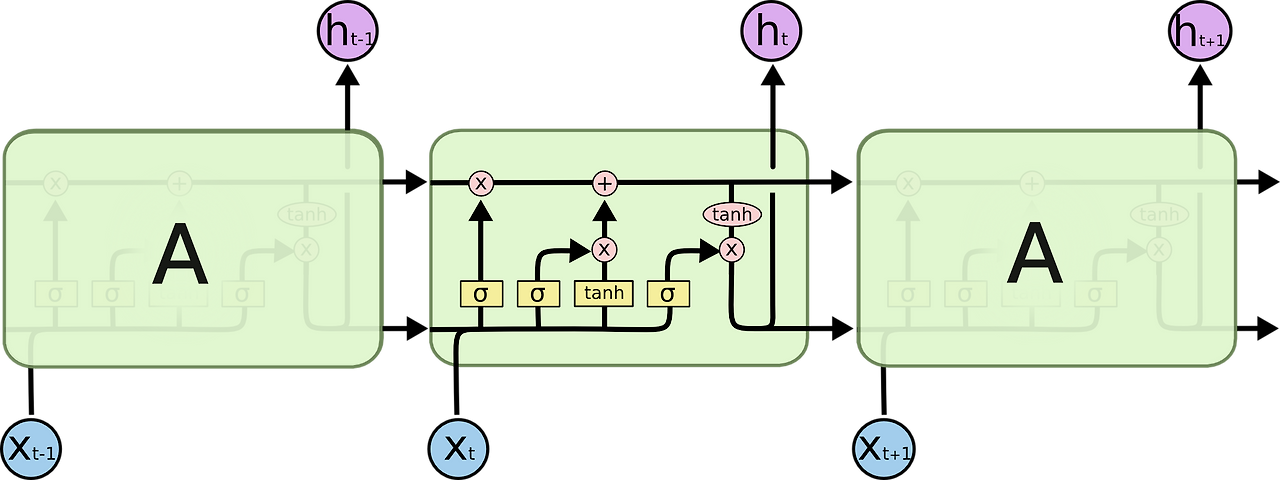
https://dgkim5360.tistory.com/entry/understanding-long-short-term-memory-lstm-kr
Long Short-Term Memory (LSTM) 이해하기
이 글은 Christopher Olah가 2015년 8월에 쓴 글을 우리 말로 번역한 것이다. Recurrent neural network의 개념을 쉽게 설명했고, 그 중 획기적인 모델인 LSTM을 이론적으로 이해할 수 있도록 좋은 그림과 함께
dgkim5360.tistory.com
1. 목적과 역할 분석
LSTM 신경망을 이용해 과거 삼성전자 조정종가 시계열 데이터를 학습하고, 이를 바탕으로 2026년 말까지의 주가를 1일 단위로 예측해 시각화하는 예제
- 문제 해결 : 시계열 데이터 예측 문제 중, 주가처럼 시점 간의 의존성이 강한 데이터를 다루기 위해 RNN 계열의 LSTM을 활용
- 실무 의의 : 금융 시계열 예측, 수요 예측, 기상 예측 등 다양한 비즈니스 도메인에 적용 가능한 기초 워크플로우를 학습할 수 있다.
그러나!
시계열(과거 종가) 만으로 주가를 예측한다는 것이 상식적인가?
1. 내부 패턴 학습
- 주가는 자기 자신 (과거 값)의 패턴 (추세, 계절성, 되먹임성)을 일정 부분 따라간다.
- 따라서 완전한 설명 변수 없이도 '어떤 경향이 이어질 것인가' 정도만 예측하는 데는 유의미하다.
2. 한계와 리스크
- 외생변수 고려 : 금리, 환율, 경쟁사 실적, 정치+사회 이슈, 투자자 심리 등 (최근 테슬라와 삼성전자의 대형 계약 체결 이슈....와 같은) 다양한 or 예상하지 못하는 요인이 존재
- 순수 시계열 모델은 이런 급변 요인을 반영하지 못해 '검증 되지 않은 뉴스'나 '돌발 이벤트' 앞에선 큰 오차를 낸다.
3. 더 정확하게 예측하고 싶다면?
* 단계적 접근
(1) 먼저 시계열 모델 (ARIMA, LSTM)로 기본 추세 파악
(2) 그 위에 종목별 거래량, 업종 지수, 뉴스 감성지표, 매크로 데이터 등을 멀티 인풋 모델 ( Multivariate LSTM 등)로 결합
2. 필수 라이브러리 분석
sklearn.preprocessing.MinMaxScaler : 종가 데이터 정규화 (학습 안정성 높이는 용도)
tensorflow.keras.models.Sequential : 순차 모델 생성 (LSTM + Dense 레이어)
tensorflow.keras.layers.LSTM : 시계열 패턴 학습용 순환 신경망 셀
tensorflow.keras.layers.Dense : 출력층 (회귀 예측값 1개)
3. 주요 기능 분석
1. 데이터 로딩 및 전처리
- csv파일에서 날짜, 조정 종가만 추출 -> date를 인덱스로 변환
- MinMaxScaler로 0~1 범위 정규화
2. 시퀀스 데이터 생성
- 과거 60일치 (sequence_len) 가격을 입력 (x), 그 다음날 가격을 타깃(y)으로 분할
- LSTM 입력 형태인 (샘플 수, 타임스텝, 피쳐 수)로 reshape
3. LSTM 모델 구성 및 학습
- LSTM 유닛 50개, return_sequences=False (마지막 타임스텝 출력만 사용)
- 출력층 Dense(1) -> 손실함수 MSE, 최적화기 Adam
4. 미래 예측 루프
- 마지막 60일 시퀀스를 시작점으로, 반복적 1일 예측, -> 스케일링 역변환 후 저장
- 주말 스킵 로직 포함
5. 결과 시각화
- 실제 주가와 예측 주가를 한 그래프에 그려 변화 추이 비교
3. 코드 해석
# lstm_samsung.py
# LSTM모델을 이용한 삼성전자 주가 예측
# 라이브러리
import pandas as pd # 데이터 프레임 생성 조작
import numpy as np # 수치 배열 연산
import matplotlib.pyplot as plt # 그래프 시각화
from sklearn.preprocessing import MinMaxScaler # 정규화
from tensorflow.keras.models import Sequential # 순차 모델 생성기
from tensorflow.keras.layers import LSTM, Dense # LSTM 셀, 출력층 레이어
from datetime import datetime, timedelta # 날짜 계산 유틸
# 데이터셋
df = pd.read_csv('assets/samsung_stock.csv') #csv 파일에서 모든 컬럼 로드
df['Date'] = pd.to_datetime(df['Unnamed: 0']) # 'Unnamed: 0' 열을 datetime 타입으로 변환
df = df[['Date', 'Adj Close']].sort_values('Date') # 날짜, 조정종가 추출 및 날짜 순 정렬
df.set_index('Date', inplace=True) # Date를 인덱스로 설정
# 정규화(0~1) : 학습 안정성 향상을 위해
scaler = MinMaxScaler() # 스케일러 객체 생성
scaled_data = scaler.fit_transform(df[['Adj Close']]) # 조정 종가 정규화
# LSTM 학습용 시퀀스 데이터 생성 (과거 60일 > 다음날 예측)
sequence_len = 60 # 입력 시퀀스 길이 과거 N일
X, y = [], [] # 빈 리스트로 초기화
for i in range(sequence_len, len(scaled_data)): # 시퀀스를 만들 수 있는 구간만큼 반복
X.append(scaled_data[i-sequence_len:i, 0]) # 과거 60일치 종가를 x에 추가
y.append(scaled_data[i, 0]) # 타겟 : 다음날의 종가, 61번째 날 종가를 y에 추가
# 독립변수 / 종속변수 numpy 배열로 변환
X, y = np.array(X), np.array(y)
# LSTM 입력 형태로 reshape (samples, time steps, features)
X = X.reshape(
X.shape[0], # 샘플 수 : 전체 데이터셋에서 학습에 사용할 입력 시퀀스의 개수
X.shape[1], # 타임 스텝 : 하나의 시퀀스에 포함되는 과거 날짜 수
1 # 피쳐 수 : 변수의 개수 (조정 종가)
)
# LSTM 모델 구성
model = Sequential() # 순차 모델 시작
model.add(
LSTM(
50, # 유닛 수
return_sequences=False, # 마지막 시점 출력만 사용
input_shape=(X.shape[1], 1) # 60일의 1차원 시계열 입력 (60, )
)
)
model.add(Dense(1)) # 예측값 1개, 회귀 예측값
# 모델 컴파일 및 학습
model.compile(optimizer='adam', loss='mean_squared_error')
# 모델 훈련 (10회 학습)
model.fit(X, y, epochs=10, batch_size=32, verbose=1)
# 미래 예측을 위한 초기 시퀀스 준비 (마지막 60일)
last_sequence = scaled_data[-sequence_len:] # 마지막 60일의 정규화된 값
forecast_sequence = last_sequence.reshape(1, sequence_len, 1) # LSTM 입력형태로 reshape
# 미래 날짜와 예측값 저장 변수 초기화
last_date = df.index[-1] # 현재 데이터의 마지막 날짜
target_date = datetime(2026, 12, 31) # 예측 종료 날짜
future_dates = [] # 예측 날짜 리스트
future_predictions = [] # 예측 주가 리스트
# 1일씩 반복 예측 루프
while last_date < target_date:
next_pred = model.predict(forecast_sequence)[0][0] # 다음날 예측값
future_predictions.append(next_pred) # 예측 결과 리스트에 저장
last_date += timedelta(days=1) # 날짜 1일 증가
while last_date.weekday() >= 5: # 주말(토/일) 스킵
last_date += timedelta(days=1)
future_dates.append(last_date) # 평일 날짜만 추가
next_seq = np.append(forecast_sequence[0, 1:, 0], next_pred) # 시퀀스 갱신 : 맨 앞값 제거하고 예측값 추가
forecast_sequence = next_seq.reshape(1, sequence_len, 1) # 다시 reshape1q1`
# 예측 결과를 역정규화 -> 실제 가격 단위 (원)로 변환
predicted_prices = scaler.inverse_transform(
np.array(future_predictions).reshape(-1, 1)
)
# 결과 시각화
plt.rc("font", family='Malgun Gothic')
plt.figure(figsize=(15, 6))
plt.plot(df.index, df['Adj Close'], label='실제 주가')
plt.plot(future_dates, predicted_prices, label='LSTM 예측 주가', linestyle='--')
plt.title('LSTM모델로 예측한 2026년까지의 삼성전자 주가변동그래프')
plt.xlabel('날짜')
plt.ylabel('조정종가 (원)')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
4. 코드 세부 학습
X.reshape(samples, timesteps, features)LSTM(또는 RNN 계열) 레이어는 입력을 3D 텐서로 기대한다.
- samples : 독립적인 "학습 예제"의 개수
- timesteps : 각 예제에서 시간에 따른 관측치(시퀀스)의 길이
- features : 각 시점(time step)마다 관측되는 변수(피처)의 개수 (이 코드에서는 '조정 종가' 하나만)
- 지금은 ‘Adj Close’ 단일값만 쓰니까 한 시점 당 관측 변수는 1개
- 만약 거래량(volume), 고가, 저가도 같이 쓴다면? features = 3이 되고 reshape 마지막 축을 3으로 바꿔주면 된다.
원래 X의 모양은 (num_samples, 60) 이다.
- num_samples: 전체 시계열을 60일씩 짤라 만든 예제 수
- 60 : 각 예제에 들어있는 과거 일수(타임스텝)
Q. 예측용 시퀀스 생성 & 갱신 로직 ?
# 1) 마지막 60일치 데이터를 뽑아와서
last_sequence = scaled_data[-sequence_len:]
# └─ shape: (60, 1)
# 2) LSTM 모델에 넣으려면 (1, 60, 1)로 reshape
forecast_sequence = last_sequence.reshape(1, sequence_len, 1)
# └─ samples=1, timesteps=60, features=1
# 3) 하루 예측 후 시퀀스를 슬라이딩 윈도우 방식으로 갱신
next_pred = model.predict(forecast_sequence)[0][0]
# 이렇게 뽑은 스칼라 예측값을
# 기존 시퀀스에서 맨 앞(가장 오래된 값)만 빼고 뒤에 붙여요.
next_seq = np.append(
forecast_sequence[0, 1:, 0], # 이전 59일치
next_pred # 오늘 예측값
)
# shape: (60,)
# 다시 (1, 60, 1)로 reshape해서 다음 예측에 사용합니다.왜 이렇게 할까?
- 한 번 예측하고 나면, 그 예측값을 미래 시퀀스의 일부로 넣어야 다음날 예측이 가능하기 때문!
5. 코드 개선 및 발전 아이디어 고민
1. 시계열 데이터 분할 & 검증 강화해보기
현재 전체 데이터로 학습만 수행함.
train/test로 나눌 때, 랜덤이 아닌 시간 순서대로 나눠야 한다.
만약 전체 시퀀스 수가 1000개라면
# 1) split 비율 정하기 (예: 80% 학습, 20% 검증)
train_size = int(len(X) * 0.8) # = 800
# 2) 앞쪽 800개는 train, 뒤쪽 200개는 test
X_train, X_test = X[:train_size], X[train_size:]
y_train, y_test = y[:train_size], y[train_size:]
# 3) 모델 학습
model.fit(X_train, y_train, epochs=10, batch_size=32, verbose=1)
# 4) test 데이터로 성능 평가
loss = model.evaluate(X_test, y_test, verbose=0)
print(f"Test MSE: {loss:.4f}")- 처음부터 중간 -> train
- 중간부터 끝 -> test
+ ) sklearn.model_selection.TimeSeriesSplit 으로 교차 검증 (여러 시점 분할)을 할 수도 있고, walk-forward validation 이라 부르는, 점진적 확장 검증도 있다.
+ ) 궁금하니까 동일한 시계열 데이터 (삼성전자) 를 단순 훈련/검증 분할, walk-forward validation, sklearn TimeSeriesSplit 로 평가해보자! - 얼마나 안정적으로 미래를 예측할 수 있는지 평가하는 다양한 관점 제공
* Walk-Forward Validation
- 시계열 데이터에 특화된 검증 기법
- 걸어가는 식으로 매 단계마다 학습 구간을 늘려가며 테스트를 수행한다.
- 예를 들어 전체 데이터가 100개라면:
- 처음 60개 학습 → 61번째 예측 → 오차 기록
- 처음 61개 학습 → 62번째 예측 → 오차 기록
- …
- 처음 99개 학습 → 100번째 예측 → 오차 기록
- 이렇게 각 시점마다 재학습하고 예측한 뒤 오차를 평균 내면, 모델이 시계열 변동을 얼마나 잘 따라가는지 평가할 수 있다.
* sklearn.model_selection.TimeSeriesSplit
- 사이킷런이 제공하는 시계열용 교차검증 클래스
- n_splits=K로 지정하면, 시간 순서를 유지하며 K개의 학습/테스트 구간을 자동으로 나눠준다.
- 예를 들어 n_splits=3이면:
- Fold1: train=첫 25%, test=다음 25%
- Fold2: train=첫 50%, test=다음 25%
- Fold3: train=첫 75%, test=마지막 25%
각 Fold마다 모델을 학습·평가해 줌으로써, 시계열 특성을 지키면서도 교차검증 효과를 얻을 수 있음
# lstm_samsung_evaluation.py
# - 삼성전자 주가 시계열을 LSTM으로 예측하고
# 1) 단순 train/test 분할
# 2) walk-forward validation
# 3) sklearn TimeSeriesSplit
# 세 가지 방식으로 평가해 봅니다.
import pandas as pd # 데이터프레임
import numpy as np # 수치 계산
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import TimeSeriesSplit
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
import tensorflow as tf
import random
#— 1. 시드 고정 및 세션 초기화 —#
SEED = 42
random.seed(SEED)
np.random.seed(SEED)
tf.random.set_seed(SEED)
tf.keras.backend.clear_session()
#— 2. 데이터 로딩 & 전처리 함수 정의 —#
def load_preprocess(path, seq_len=60):
# 1) CSV 로드 및 날짜 인덱스 설정
df = pd.read_csv(path)
df['Date'] = pd.to_datetime(df['Unnamed: 0'])
df = df[['Date', 'Adj Close']].sort_values('Date').set_index('Date')
# 2) MinMax 정규화
scaler = MinMaxScaler()
scaled = scaler.fit_transform(df[['Adj Close']])
# 3) 시퀀스 생성
X, y = [], []
for i in range(seq_len, len(scaled)):
X.append(scaled[i-seq_len:i, 0])
y.append(scaled[i, 0])
X = np.array(X)
y = np.array(y)
# 4) LSTM 입력 형태로 reshape
X = X.reshape((X.shape[0], X.shape[1], 1))
return X, y, scaler, df.index[seq_len:]
#— 3. LSTM 모델 생성 함수 —#
def build_lstm(input_shape):
model = Sequential([
LSTM(50, return_sequences=False, input_shape=input_shape),
Dense(1)
])
model.compile(optimizer='adam', loss='mean_squared_error')
return model
#— 메인 실행 —#
if __name__ == "__main__":
# 데이터 불러오기
X, y, scaler, dates = load_preprocess('assets/samsung_stock.csv')
# 1) 단순 Train/Test 분할 (80/20)
split = int(len(X)*0.8)
X_train, X_test = X[:split], X[split:]
y_train, y_test = y[:split], y[split:]
model1 = build_lstm((X.shape[1], 1))
model1.fit(X_train, y_train, epochs=10, batch_size=32, verbose=1)
pred1 = model1.predict(X_test)
mse1 = mean_squared_error(y_test, pred1)
print(f"[단순분할] Test MSE: {mse1:.5f}")
# 2) Walk-Forward Validation
# – 매 시점마다 모델 재학습 → 다음 시점 예측
errors_wf = []
for i in range(split, len(X)):
# i는 예측하려는 시퀀스 인덱스
Xi_train, yi_train = X[:i], y[:i]
Xi_test, yi_test = X[i:i+1], y[i:i+1]
model_wf = build_lstm((X.shape[1], 1))
# 학습 에폭을 적게 잡아 속도 조절 가능 (여기선 5)
model_wf.fit(Xi_train, yi_train, epochs=5, batch_size=32, verbose=0)
pred = model_wf.predict(Xi_test)
errors_wf.append((yi_test[0] - pred[0,0])**2)
mse2 = np.mean(errors_wf)
print(f"[Walk-Forward] Avg MSE: {mse2:.5f}")
# 3) TimeSeriesSplit (n_splits=5)
tscv = TimeSeriesSplit(n_splits=5)
errors_ts = []
for fold, (train_idx, test_idx) in enumerate(tscv.split(X)):
Xi_train, Xi_test = X[train_idx], X[test_idx]
yi_train, yi_test = y[train_idx], y[test_idx]
model_ts = build_lstm((X.shape[1], 1))
model_ts.fit(Xi_train, yi_train, epochs=10, batch_size=32, verbose=0)
pred = model_ts.predict(Xi_test)
mse_fold = mean_squared_error(yi_test, pred)
errors_ts.append(mse_fold)
print(f"[TSplit Fold {fold+1}] MSE: {mse_fold:.5f}")
mse3 = np.mean(errors_ts)
print(f"[TimeSeriesSplit] Avg MSE: {mse3:.5f}")
#— 최종 비교 —#
print("\n=== 모델별 성능 비교 ===")
print(f"단순분할 : {mse1:.5f}")
print(f"Walk-Forward : {mse2:.5f}")
print(f"TimeSeriesSplit: {mse3:.5f}")
'Data Analysis Study' 카테고리의 다른 글
| Transformer 자연어 처리 모델 개념 및 원리 (3) | 2025.08.03 |
|---|---|
| RNN, LSTM, GRU 모델 성능 비교 | 하이퍼파라미터 구조 튜닝 및 피처 엔지니어링 (기상청 데이터) (3) | 2025.07.30 |
| RNN, LSTM, GRU 세 가지 순환 신경망 성능 비교 (IMDB 리뷰 데이터 셋) (3) | 2025.07.30 |
| IMDB 영화 리뷰 데이터셋 EDA (3) | 2025.07.29 |
| IMDB 데이터 & RNN 모델을 이용한 감성 분석 (긍정 vs 부정 리뷰 분류) (0) | 2025.07.29 |